構造化データ
序章
Web Almanacが構造化データに関する章を設けるのは今年で2年目です。昨年のコンテンツでは構造化データの概念について、その存在理由、もっとも頻繁に使用されるタイプ、そして構造化データが組織にもたらすメリットについて概説しその基礎を固めました。今年は、2022年に収集したデータを昨年の前回データと比較することで、その間に発生した傾向を把握することができました。
機械学習、とくに「自然言語処理」の分野では多くの進歩が見られるが、データを機械的に読みやすい形式で表示する必要があることに変わりはない。構造化データは、ウェブ検索やデータ連携、アーカイブなどの情報発見を支援するものです。Webサイトに構造化データを導入することで、エンジニアやWebコンテンツ制作者は容易に構造化データを利用できるようになる。
- ウェブサイトデータをより広く公開し、自動的な発見とリンクを可能にする。
- 公共研究用データのオープン化
- 組織のデータの品質が、データが発信元を離れた後も維持されるようにすること
あらゆる規模や種類の組織が、自社のコンテンツをウェブ上で発見してもらいたいと考えています。GoogleやBingなどの検索エンジンは、構造化データの利用を促進することで、データの発見力を重視しています。SEOの観点からは、データを見つけやすく、解析しやすい形で提示することが有利です。これらの利点の一部は、本章の使用例と主要コンセプトのセクションで説明することにする。
昨年の紹介では、「機械が構造化データを確実に、大規模な抽出ができるようになれば、新しくスマートなタイプのソフトウェア、システム、サービス、ビジネスが可能になる」と指摘されています。今年の章では、構造化データに関する最近発表された研究、オープンソースのフレームワーク、高品質な構造化データの生成を支援するツールなどを紹介します。
今年は、さまざまな構造化データ型の存在やそれらの構造化データ型の成長などの測定基準の最初の前年比を提供し、構造化データを使用することの進化した利点を検証しています。2021年からのデータのベースラインを持つことで、構造化データの利用がその間にどのように変化したかについての洞察を得ることができ、たとえばこの間のTikTokの成長など、興味深い傾向を観察できます。
データの注意点
構造化データはさまざまな形で表示され、特定のドメインとそれに対応するWebサイトでは、他のドメインよりも目に付きやすい場合があります。たとえば、ニュースサイトとeコマースサイトを比較してみましょう。一般に、ニュースサイトでは、もっとも重要な最新ニュースがホームページに表示されます。したがって、ニュース記事に関連する構造化データは、個々の記事の見出しにデータスニペットとして付加されたメインサイトのランディングページに存在する可能性があります。これに対してeコマースにおける構造化データは、個々の製品に関連するため、ウェブサイトの製品カタログ自体に存在することがほとんどであり、ウェブサイトのメインナビゲーションやプロモーション部分のハイレベルな検索からは、多くの点で「見えない」状態になっています。これが、構造化データの章とレポートとの関連で意識しなければならない重要な注意点です。
ウェブサイトからデータを収集するために使用される技術は、サイトの表面(ホームページなど)をかすめるだけで、サイトの完全なクロールで深部まで行かないため、必然的にサイトの深部にデータが含まれるサイトでの構造化データの使用範囲の全体像を把握することができません。将来的にはこの問題を解決し、構造化データのドメイン固有の使用に関するさらなる洞察を得るために、さまざまなドメインのサイトのサンプルを採取し、深く掘り下げていきたいと考えています。
昨年の章にあったハイレベルな注意点はまだ残っている。
-
自動生成された構造化データ: これは、コンテンツ作成システムなどの技術が、テンプレートに基づいて構造化データスニペットを自動生成する場合です。この場合、テンプレートに基づくエラーは、表示されるすべてのデータで必然的に発生することになります。
-
データフォーマットの重複: 構造化データは、JSON-LD、RDFなど、さまざまな方法で表示できます。たとえばFacebookのメタタグとRDFaセクションで、異なる方法で表示された同じタグの間で重複が、見られる可能性があることを意味します。2021年のベースラインに対して作成されたクエリに基づいて分析が行われるため、クリーニング/正規化およびデータの平坦化の影響は、同様の分析に引き継がれるものと思われます。
主要コンセプト
構造化データは豊かで複雑な分野であるため、分析に取りかかる前、このトピックの重要な概念をいくつか説明することが重要です。
リンクされたデータ
ウェブページに構造化データを追加し、ページが含む/参照するエンティティへのURIリンクを提供することで、リンクされたデータ が作成されるのです。この構造化データは相互リンクされ、セマンティッククエリを通じてより有用なものとなる。
ウェブページの内容を記述するためにリンクされたデータを追加することで、機械がウェブページをデータベースとして扱うことができるようになります。大規模なものでは、セマンティック・ウェブ に寄与しています。セマンティックウェブは、リソース記述フレームワーク(RDF)によってデータを結びつけています。これは、ウェブ上の情報を表現するためのフレームワークで、URIを使ってエンティティやその間の関係を定義します。
RDFデータモデルにおけるエンティティ間の関係は、セマンティックトリプルとして知られています。セマンティックトリプル(または単に トリプル)で、データに関する文をコード化できます。これらの表現は、主語ー述語ー目的語の形式にしたがっている(たとえば、”アレンがジョンを知っている”)。
RDFデータを取得・操作するためには、標準的なRDF問合せ言語であるSPARQLのようなRDF問合せ言語が使用できます。
後述するように、このセマンティックウェブは、ビジネスや技術に多くのチャンスをもたらす。
オープンデータ
リンクされたデータは、オープンデータとして、リンクされたオープンデータ と表現されることもあります。オープンデータとは、その名の通り、誰でも、どんな目的でも、オープンにアクセスできるデータのことです。このデータは、オープンライセンスのもとでライセンスされています。
オープンデータは、Tim Berners-Leeが提案した展開スキームである5 stars of open dataの最初のものです。オープンデータ・ハンドブックによると、最大5つ星を獲得するためには、(1)オープンライセンスの下ウェブ上で利用可能、(2)構造化データの形式、(3)非専有ファイル形式、(4)識別子としてURIを使用、(5)他のデータ源へのリンク(データ連携参照)であること、としています。
構造化データは5つ星オープンデータ計画の2つ目の星ですが、リンクデータはオープンデータの5つ星すべての要件を満たす必要があります。
セマンティック検索エンジンとリッチリザルトとその先へ
セマンティック検索エンジンとは、セマンティック検索を行うエンジンのことです。これは、検索エンジンが単語や文字列の完全一致や近傍一致を探す語彙検索とは異なるものです。セマンティック検索は、ユーザーの意図や検索語の文脈を理解し、検索の精度を向上させることを目的としています。たとえば、「ローカル ビジネス:美容院」の構造化データ・エンティティと「TG Locks n Lashes」の構造化データ・エンティティがあります。後者はビジネスネームであり、ヘアサロンというクリエイティブな名前をキーワードとして伝えていますが、検索エンジンがそのビジネスを理解するためにはほとんど役に立ちません。構造化データを使用することで、ウェブサイトは検索エンジンがその情報の文脈をより理解しやすくなり、その結果、検索ユーザーが尋ねたクエリの文脈に沿ったより良い検索結果を提供することができるようになります。GoogleとBingは、セマンティック検索エンジンの優れた例です。
Googleはセマンティック検索技術を使って、検索結果をインフォボックスで提供するために使われる知識ベースであるGoogleナレッジグラフから関連情報を提供しています。このインフォボックスは、ナレッジパネルとして知られており、多くの結果で見ることができます。このナレッジボックスは、構造化データによって有効化または強化できます。
構造化データとリンクデータを組み合わせることで実現するもう1つの検索結果が、リッチリザルトです。これらの結果は、イベント、FAQ、ハウツー、求人情報、より一層などの形で、検索結果にリッチな機能を表示します。構造化データを実装してWebページをリッチリザルトの対象にすることで、クリック率を高めることができる。下の画像は、ヘアースタジオのビジネスの詳細を構造化データにすることで、検索エンジンがそのビジネスの情報を簡単に抽出して表示し、ハイライトしてSEOを最適化できることを示しています。
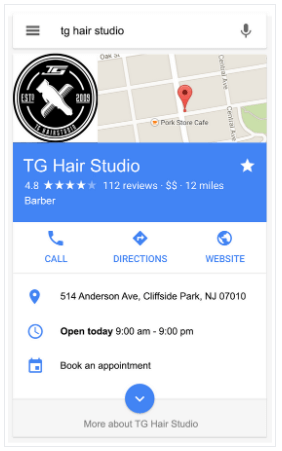
ナレッジ パネルやウェブページのリッチな結果を超えて、構造化データは、検索における ファクト クエリへの回答を可能にすることも可能です。事実に基づくクエリ検索は、異なる構造化データソースから複数のシグナルを取得し、より正確な結果をサポートできます。ここで構造化データの実装とそれを可能にするテクノロジーは、ユーザー体験を向上させるために、より速く、より信頼性の高い情報へのアクセスを提供します。
SEOの重要性、クリック率の向上、ユーザー体験の改善、解析のための機械読み取り可能なデータという組み合わせは、構造化データの実装による大きな利点を示しています。これらの重要な概念を理解することは、コンテンツプロバイダーとサイトを構築する技術者の両方にとって、より良いナビゲーションの実装方法と、ウェブページからの自動データ取得の機能を理解するのに役立ちます。
構造化データ研究
今回は構造化データの分野でどのような学術研究が行われているのか、また、構造化データが最先端の技術やサービスの開発に役立っているという記録があるのか、調査してみました。
発表された研究を探すために、Google Scholar、ConnectedPapersおよび大学ベースの引用データベースなどの学術検索ツールを使用しました。最近の出版物だけでなく、引用され続けている古い研究も探しました。
検索の結果、構造化ウェブデータの生成、管理、構築に関して実施された、引用度の高い最近の研究はあまりないことがわかりました。しかし、ナレッジグラフ、レコメンデーションエンジン、情報検索、チャットボット、説明可能なAIなどの構造化ウェブデータ(“セマンティック・ウェブ”)の応用に関する研究は、過去12か月間に行われ、今もなお増え続けています。
ウェブ構造化データは、機械可読ラベルの生成に使用できる適切な統一参照指標(URI)語彙を持つ一貫したデータを提供することによって、機械学習の分野と相乗的な関係を共有しています。私たちの検索や背景を読むと、構造化データは、機械学習アルゴリズムを学習するための高品質なウェブデータを生成するための作業と入力時間をかなり削減していることがわかります。
実用的なレベルでは、構造化データが改善された3つの分野を取り上げます。
- ナレッジグラフ
- 知識グラフを用いた質問応答
- 説明可能なAI
ナレッジグラフ
構造化されたウェブデータは、エンティティやオブジェクト間の固定語彙をドメイン固有の言語として提供し、一般にRDF形式で保存される。RDFを用いた知識グラフは、エンティティ間の関係を照会するための優れたツールであることが証明されている。たとえば、Wikidated 1.0は、Wikipediaの改訂履歴を保存するためにWeb構造化データを使用した進化する知識グラフです。その対応する論文は、RDFタプルの追加と削除のセットとしてページの改訂を集約するプロセスについて話しています。著者らは、wikipediaのダンプを知識グラフに変換する方法をオープンソースで公開しています。doordashエンジニアリングによって行われた応用研究では、知識グラフを使うことで検索性能が劇的に向上することが実証されています。
知識グラフを用いた質問応答
質問応答システムは、エンドユーザーが自分の質問に対する答えを見つけることを可能にする。知識グラフの上に構築された質問応答システムは、知識グラフに格納された豊富で構造化されたデータへアクセスすることを可能にします。知識グラフにRDFトリプルとして格納された情報を問い合わせるために、SPARQLなどの問い合わせ言語がしばしば使用される。
しかし、SPARQLのクエリを書くことは、エンドユーザにとって退屈で困難な場合がある。そこで、自然言語質問(NLQ)は、知識グラフへの問い合わせにおける数々の複雑さを克服することができる魅力的なソリューションです。本研究では、2つの主要なフェーズからなるKGベースの質問応答システム(KGQAS)を提案する。1) オフラインフェーズと、2) 意味解析フェーズです。
オフラインフェーズでは、自然言語の質問を半自動で正式なクエリーパターンに変換することを目的とし、セマンティックパージングフェーズでは、機械学習を活用して予測モデルを構築する。このモデルは、最初のフェーズの出力に対して学習されます。これにより、与えられた質問に対してもっとも適切なクエリパターンを予測することができる。評価のために、SalzburgerLand KGを実際のユースケースとして使用する。これはスキーママークアップボキャブラリーを用いて構築された実世界の知識グラフであり、その主な焦点はオーストリアのザルツブルク地域の観光エンティティを記述した構造化データの自動化です。
説明可能なAI
Explainable AIは、AIモデルの意思決定を説明することに重点を置いています。もっとも、AIモデルは一般に公開されていないため、その判断の根拠を示すことはできません。セマンティックウェブの上に構築された知識グラフのおかげで、エンティティ間の見つけにくい関係を見つけることができます。これらは、モデルの結果を遡るための「グランドトゥルース」として使用されます。もっとも一般的なアプローチは、ネットワーク入力やニューロンをオントロジーのクラスやウェブ構造化データのエンティティにマッピングすることです。
参考文献:
- ナレッジグラフ: Wikidated 1.0: ウィキデータの改訂履歴の進化する知識グラフ・データセット。
- 知識グラフを用いた質問応答: 知識グラフを用いた質問応答。観光産業におけるケーススタディ。
- 構造化データを用いた説明可能なAI: 説明可能な機械学習モデルのためのセマンティックウェブ技術: 文献レビュー
構造化データのオープンソース利用
構造化データの利用に大きく依存している注目のプロジェクトは、以下の3つです。
- オープンソース・メタデータ・フレームワーク(OMF) - OMFは、オープンソースドキュメントに関するデータ/メタデータを収集することを目的としており、通常、ドキュメントの説明に使用される構造化されたデータ形式で保存されます。OMFは、存在する多くのオープンソースドキュメントプロジェクトのための洗練されたカードカタログのようなシステムとして機能することが期待されています。
- DBpedia は、構造化されたウェブデータに関連するデータセット、ツール、サービスの集合体です。現在までに2億2,800万以上の自由利用可能な実体が含まれています。メインのDBpediaナレッジグラフは、ウィキペディアのクリーンなデータを包含しています。DBPediaは、サポートされているすべてのWikipediaの言語で利用可能で、年間平均600kファイル以上のダウンロードがあります。DBpediaの上に構築されたいくつかのオープンソースツールは、データアクセス、バージョン管理、品質管理、オントロジー可視化、リンクのインフラストラクチャを提供します。
- Wikidata は、WikipediaなどのWikimediaプロジェクトの構造化データを格納しています。ドキュメント指向のデータベースで、構造化されたウェブデータを格納することに重点を置いています。
使用例
構造化データの実装は、多くの分野で広く有益であるが、そのうちのいくつかにこのセクションで焦点を当てることにする。これらの分野の多くは、リンクデータおよび構造化データの性質上、重複していることに注意することが重要です。
データ連携
データを構造化しリンクさせることで、場所、イベント、人、コンセプトなどを識別子を用いて指定しながら、他のデータソースからデータを引用することができ、その結果、メタデータの記述にアクセスしやすくなる。そして、このデータはより共有しやすく、再利用しやすくなる。
データリンクにより、異なるソースから情報を収集し、より豊かで有用なデータを作成することができる。これは構造化データのおかげであり、そのグローバルでユニークな識別子によって、機械は異なるタイプのデータの関係を読み取り、理解することができる。これにより、よりつながりのあるウェブ上の関係を作り出すことができるのです。
検索エンジン最適化&ディスカバリー性
検索エンジン最適化(SEO)は、検索エンジンからより良い結果を得られるように、ウェブページのコンテンツを構築することに焦点を当てた分野です。SEO対策がうまくいけば、検索エンジンの検索結果ページ(SERP)で上位に表示される可能性があるので、当然、これは発見性にとって非常に重要なことです。SERPは、検索クエリからタイトル、URL、メタディスクリプションが表示される場所です。
ウェブページに構造化データを追加することで、ウェブページを検索エンジンに最適化するとともに、SERPから見えるように余分なコンテンツを追加できます。この追加コンテンツはさまざまな形で提供され、そのうちのいくつかは以前ナレッジパネル、リッチスニペット、関連質問で議論されています。
検索エンジンからWebページへのトラフィックを増やすには、構造化データによる発見力の向上が欠かせません。そのため、企業やeコマースページは、これらの技術に大きな価値を見出すことができるだろう。
Eコマース&ビジネス
Eコマースのウェブページに構造化データを実装することは、ビジネスに関わる人々にとって非常に有益なことです。これらのビジネスでSEO対策に広く利用されている構造化データ型は多数あります。
ローカル ビジネスは構造化データ型で、関連する検索クエリ(例:「ダブリンの人気レストラン」)の際に構造化データ型へ入力した詳細をGoogleナレッジパネルに返す可能性があります。このタイプはまた、営業時間、ビジネス内の異なる部署、ビジネスに対するレビューを持つ可能性があり、これらはすべてマップアプリの検索クエリから同様に返される可能性があります。
商品は構造化データ型で、検索クエリで豊富な結果を返すことができるという点で、LocalBusinessと同様に機能する。これらの結果には、価格、在庫状況、レビュー、評価、そして画像さえも検索結果に含めることができます。これらの追加要素により、製品が検索から注目される可能性がはるかに高くなります。製品属性は、製品同士を結びつけ、検索クエリに適切に対応することで、発見力を高めることができます。
これらは、eコマースにおける構造化データの使用例のほんの一例です。eコマースページが実装することで利益を得られる構造化データ タイプは、他にもたくさんあります。
1年を振り返って
構造化データは、出版社が事前に定義された方法でデータを適合させ、提示することができるメタレベルのスキーマを記述するフォーマットと標準によって支えられています。本章の分析では、RDFa、OpenGraph、JSON-LD、その他の確立されたフォーマットが使用されています。

RDFaとOpen Graphは、それぞれモバイルページの62%と57%を占めており、依然として大多数を占めています。構造化データ型はモバイルとデスクトップのページで一貫して見られますが、Microformatsとmicroformats2はこの章で調べた他の構造化データ型ともっとも異なっています。Microformatsはモバイルページで86%著しく、一方microformats2はモバイルページで171%著しくなっています。これらの2つの構造化されたデータ・タイプは、私たちのセットで見つかったものの小さな割合を構成しています。
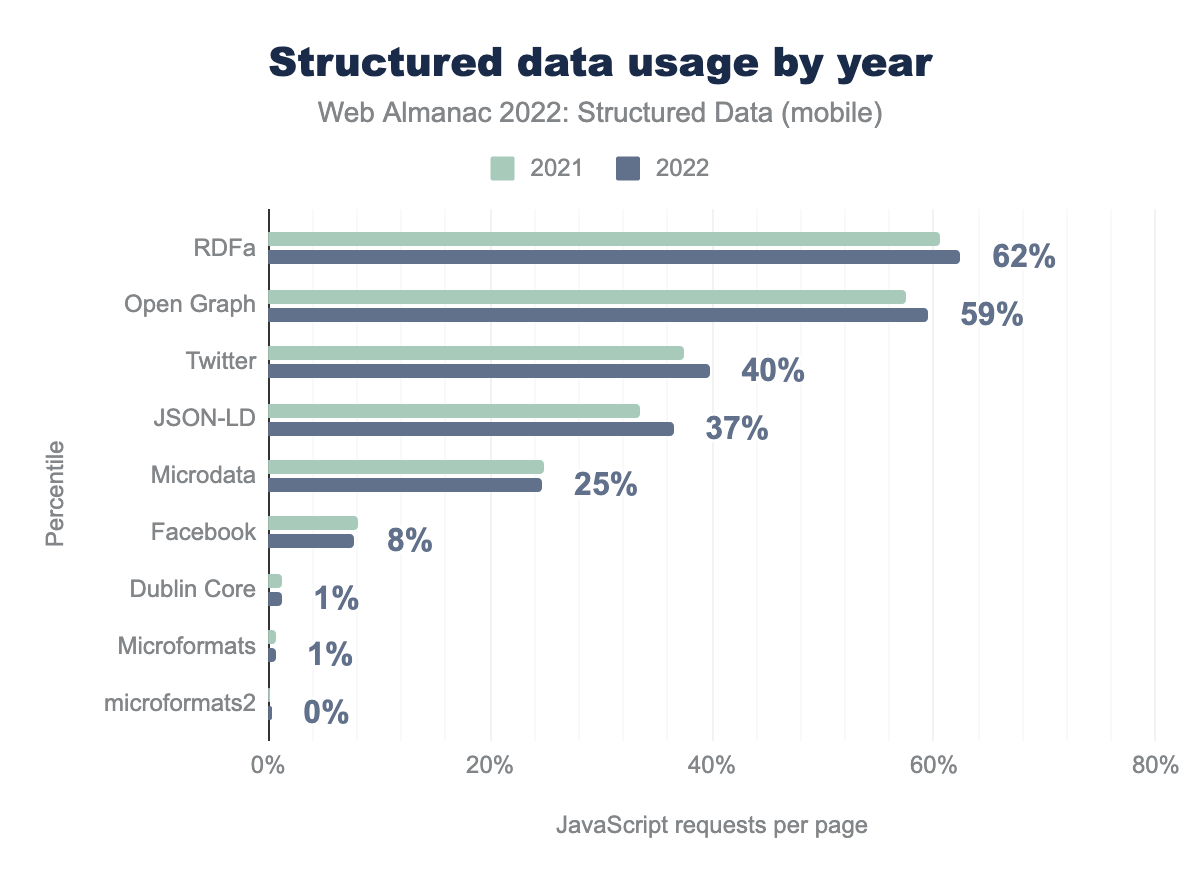
Twitterメタタグ(37%から40%に増加)やJSON-LD(2021年の全体34%から2022年の全体37%にカバー率が増加)など、これらの広く使われている構造化データ型の全般的な増加が見て取れる。Microdata、Facebook meta tags、Dublin Core、Microformatsなど、あまり普及していない構造化データ型については、利用率がやや減少しています。デスクトップの動きも非常に似ています。
以下の表は、過去1年間に構造化データ形式が変更された主なものを示しています。変更のあったタイプのみ記載しています。
| データ型 | 変更 |
|---|---|
| RDFa |
RDFa の基本フォーマットに変更はありませんが、データカタログ用語集 (DCAT) のバージョン 3 には重要な更新が含まれていました。DCAT は、「ウェブ上で公開されたデータカタログ間の相互運用性を促進するために設計された RDF ボキャブラリー」です。これは、ウェブ上のオープン データセットの可用性が高まっているため、重要な意味を持ちます。データセットの内容全体を記述できるようになると、公共データセットの発見性、ひいては有用性が大幅に高まり、連携した検索や配布がより可能になるのです。
参考文献:
|
| JSON-LD |
過去1年間の更新・追加内容は軽微なものであった。もっとも、「OrganizationのサブタイプとしてOnlineBusinessを追加し、OnlineBusinessのサブタイプとしてOnlineStoreを追加した」というように、メンテナンスとコンテキストの小さな拡張に関連するものであった。
参考文献: |
全体としては、表にあるように主要なデータタイプの定義にほとんど変化はないが、特定のドメインでいくつかのフォーマットが進化している。
それぞれのタイプについて、もう少し掘り下げてみましょう。
RDFa

foaf:image が使われ、 foaf:document が0.36%、0.30%、 sioc:item が0.24%、0.20%、 schema:webpage が0.11%、0.12%、 image が0.09%、0.10%、og:website が0.06%、0.08%、listitem が0.08%、0.08%、breadcrumblistが0.07% 、0.07%、webpageが0.04%、0.04%、personは0.03%、0.03%、schema:articleで0.03%、0.03%, skos:conceptは0.04%、0.03%、v:breadcrumb が0.04%と0.03%、そして最後にsioc:useraccountが2021年に0.03%、2022年で0.02%のページで使用されています。RDFaのタイプを評価すると、foaf:imageは他のどのタイプよりも多くのページに存在していますが、2021年以降、セットに含まれるページの割合が減少していることがわかります。これは次の2つのタイプ、foaf:documentとsioc:itemにも当てはまり、使用率がわずかに減少しています。他の多くのタイプは、RDFaが全体として見ているように、使用率がわずかに増加していることがわかります。
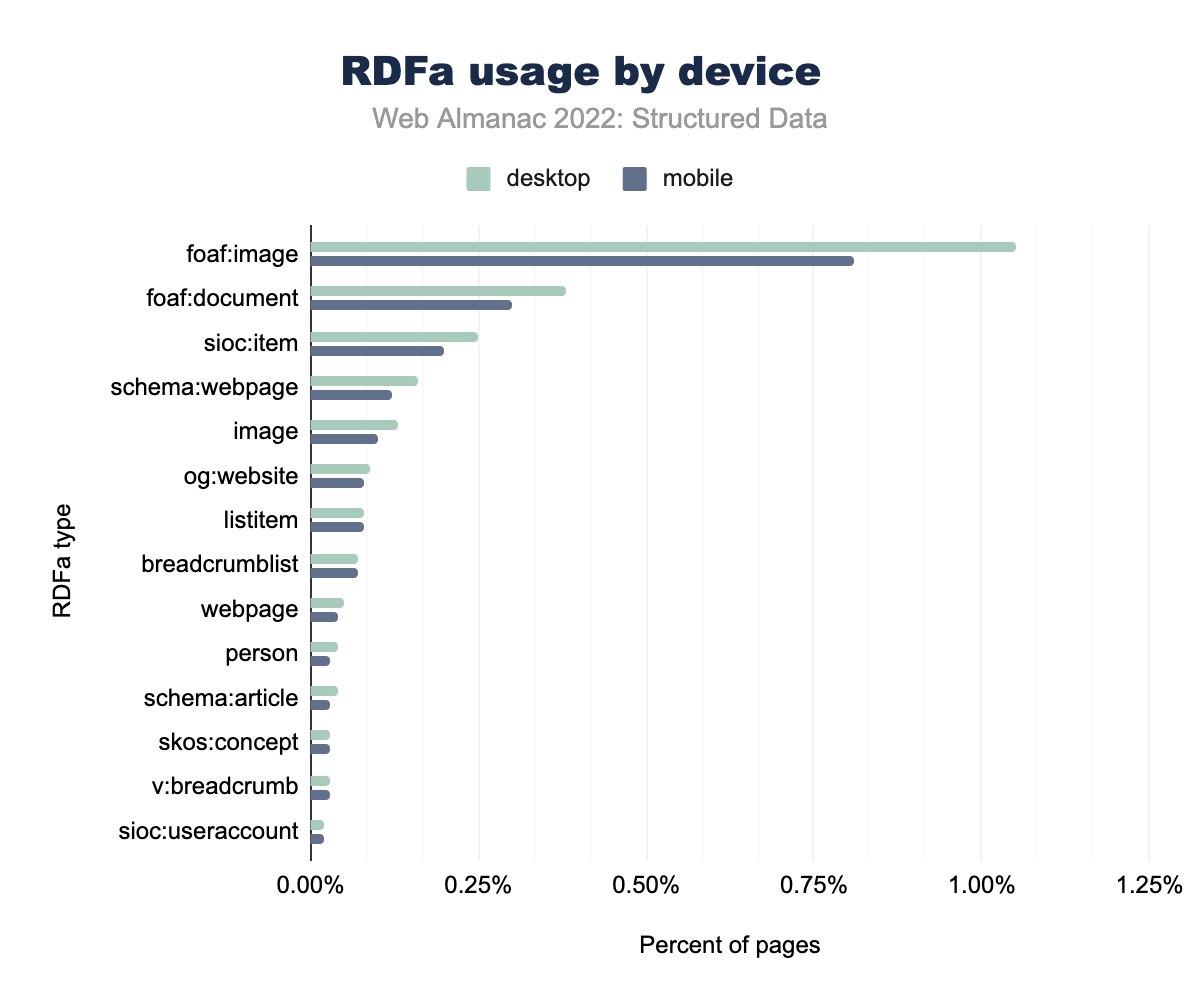
foaf:image がデスクトップの1.05% とモバイルの0.81% で、foaf:documentが0.38%と0.30%で、sioc:itemが0.25%と0.20%で、schema:webpage が0.16%と0.12%、imageが0.13%と0.10%、og:websiteが0.07%と0.08%、listitemが0.09%と0.08%、breadcrumblistが0.08%と0.07%、 webpage が0.05%、0.04%、 personが0.03%、0.03%、 schema:article が0.04%と0.03%、skos:concept が0.04%、0.03%、 v:breadcrumb が0.03%、0.03%、そして最後に sioc:useraccount がデスクトップとモバイル両方のページの0.02% で使用されています。RDFaはデスクトップでより顕著で、foaf:imageはモバイルページの0.81%に対し、デスクトップページの1%に出現しています。その他のRDFaタイプは、モバイルよりもデスクトップページでの出現率がわずかに上昇しましたが、og:websiteは例外で、モバイルページでは0.08%、デスクトップページは0.07%で先に到達しています。
ダブリンコア
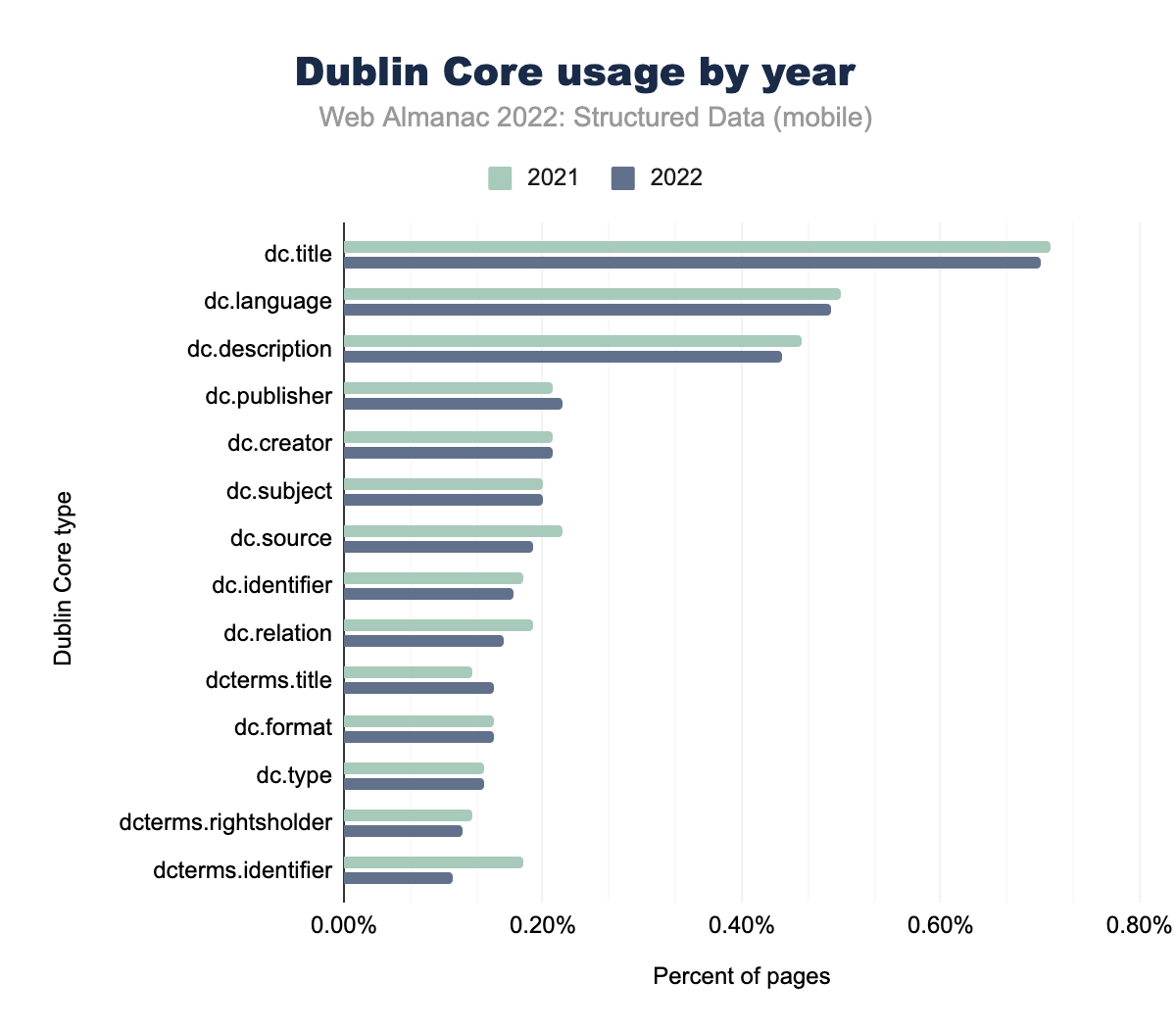
dc.titleが使用されたことを示す棒グラフ。dc.languageが0.50%と0.49%、dc.descriptionが0.46%、0.44%、dc.publisher は0.21%と0.22%、 dc.creatorは0.21%と0.21%、 dc.subjectは0.20%と0.20%、 dc.sourceは0.22%と0.19%、dc.identifierが0.18%と0.17%、dc.relationが0.19%と0.16%、dcterms.titleが0.13%と0.15%、dc.formatが0.15%と0.15%、doc. typeが0.14%と0.14%、 dcterms.rightsholderが0.13%と0.12%、そして最後に dcterms.identifier が2021年にはモバイルページの0.18%で、2022年には0.11%で使用されることになりました。ダブリンコアの属性タイプの使用率は、もっとも顕著な属性タイプで非常によく似たままです。注目すべき例外はdcterms.identifier で、2021年の0.11%から2022年にはモバイルページで0.18%に増加しています。割合としては小さいですが、これは私たちのセットで合計すると約15,000の使用回数になります。この増加は、デスクトップ・ページでも見られましたが、それほど大きくはなく、2021年の0.14%から2022年の0.18%になりました。
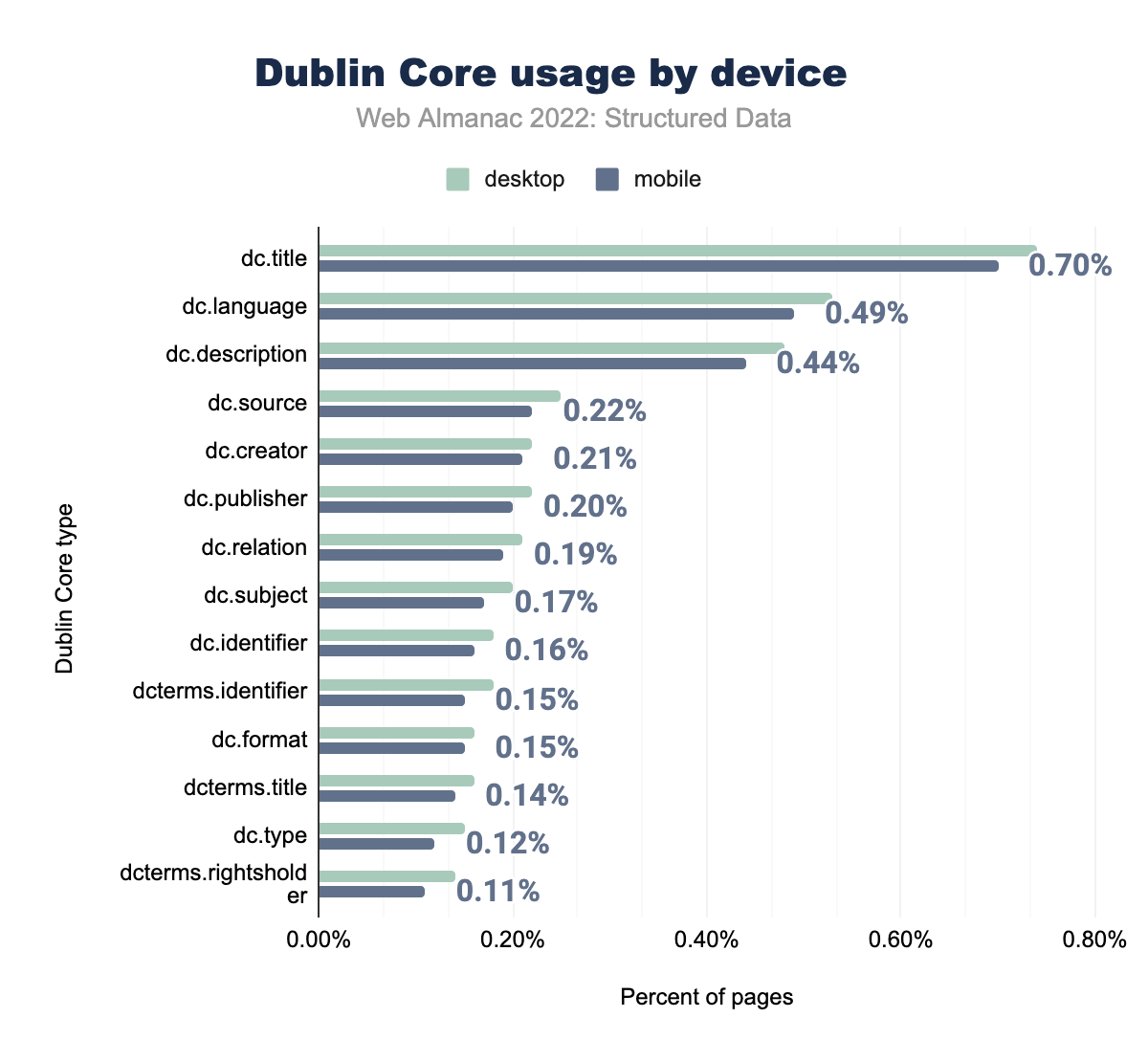
dc.titleがデスクトップページの0.74%、モバイルページの0.70%で使用されていることを示しています。dc.languageは0.53%と0.49% で、 dc.descriptionは0.48%と0.44%、dc.publisherは0.22%と0.22%、 dc.creatorは0.22%と0.21%、 dc.subjectは0.20%と0.20%、 dc.sourceは0.25%と0.19%、 dc.identifierは0.18%と0.17%、 dc.relationは0.21%と0.16%、dcterms.titleは0.16%と0.15%、dc.formatは0.16%と0.15%、dc.typeは0.15%と0.14%、dcterms.rightsholderは0.14%と0.12%、最後に dcterms.identifier はデスクトップのページの0.18%, モバイルページの0.11% で使用されました。その他、ダブリンコアのタイプはモバイルページとデスクトップページでほぼ同じで、前年と比較して出現率が若干増加しているのは共通しています。
オープングラフ

og:image が使用され、 og:image:width が13%、14%、 og:image:height が13%、14%、 og:image:secure_url が6%、6%、 og:image:type が2%、5%、最後に og:image:altが2021年に2%、2022年は3%のモバイルページで使用されたことを表しています。Open Graphタグは、広く使用されるようになりました。これらのタグのうちもっとも一般的なのは、og:titleであり、og:url、og:typeとともに、セット内の全ページの半数以上に出現しています。もっとも多くの増加幅は小さく、例外的に og:image:type は2021年以降、モバイルページで3倍以上になっています。これはデスクトップでも同様で、1年の間に1.6%から5.4%になりました。

og:imageがデスクトップページの40%とモバイルページの39%、og:image:widthがそれぞれ15%と14%、og:image:heightが15%と14%、 og:image:secure_url が6%と6%、 og:image:type が両方の5%で使われ、最後に og:image:alt がデスクトップとモバイルページの両方で3%使われていたことを表します。モバイル、デスクトップともに上位10位までの各Open Graphタイプの利用が増加し、2021年以降のOpen Graphの相対的な成長率は1.5%という結果になりました。
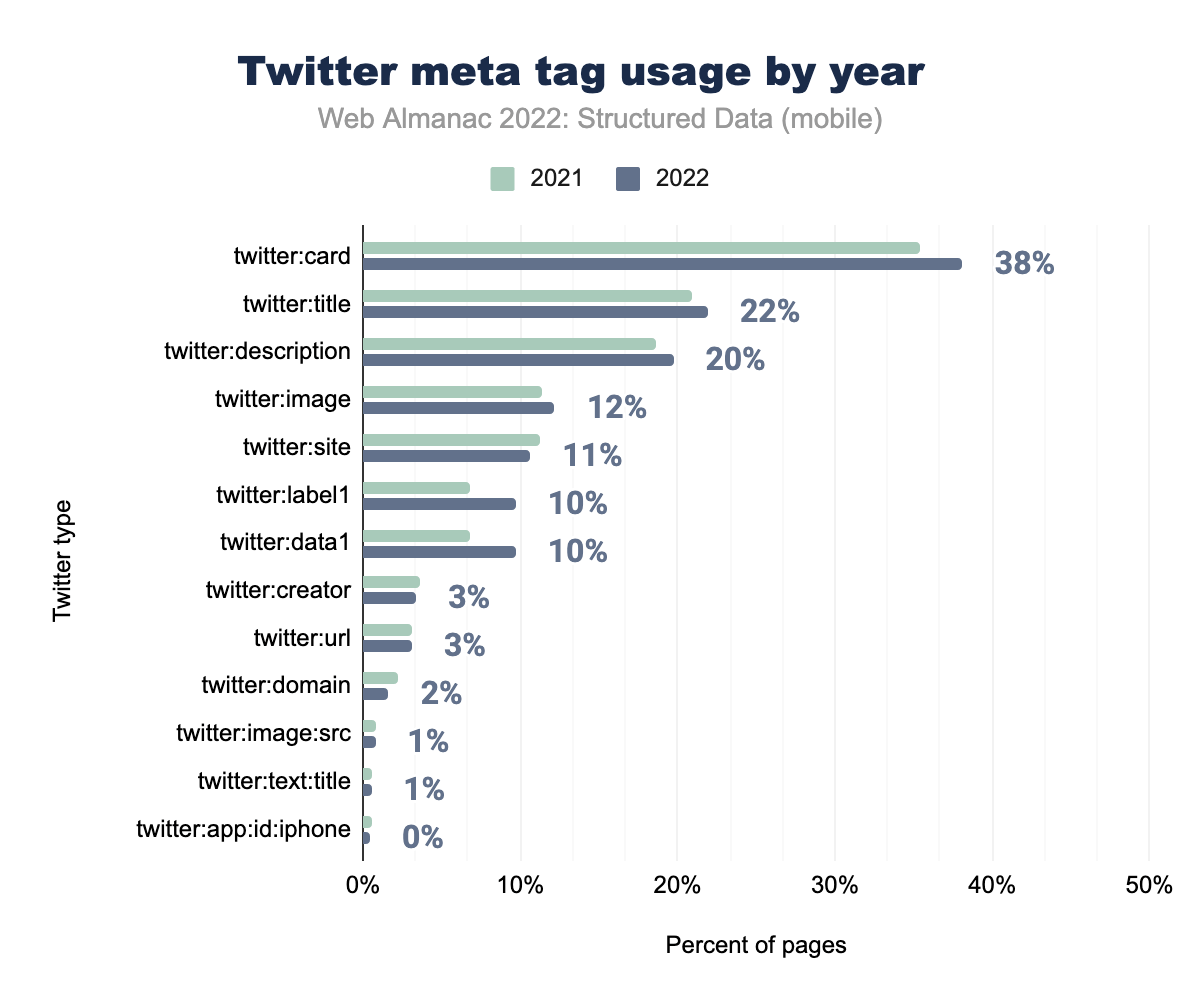
twitter:cardが使用されたことを示す棒グラフ。twitter:titleが21%、22%、twitter:descriptionが19%と20%、 twitter:imageが11%と12%、 twitter:siteが11%と11%、 twitter:label1が7%と10% 、twitter:data1は7%と10%、twitter:creatorは4%と3%、twitter:urlは3%と3%、twitter:domainは2%と2%、twitter:image:srcは1%と1%、twitter:text:titleは1%と1%、最後に twitter:app:id:iphone が2021年にはモバイルページの1%、2022年には0%のページで使用されていたことが分かりました。Twitterのメタタグは再び、一般的な使用率の増加パターンにしたがっており、とくにtwitter:card、twitter:title、twitter:description、twitter:imageの共通タグで増加しています。注目すべきは、twitter:label1とtwitter:data1で、ともに2021年の7%から2022年にはモバイルページで10%に増加していることが確認できます。

twitter:cardがデスクトップページの39%、モバイルページの38%で使用されていることを示しています。twitter:titleが22%と22% で、twitter:descriptionが20%と20% で、twitter:imageが12%と12% であった。twitter:siteは13%と11%、twitter:label1は10%と10%、twitter:data1は10%と10%、twitter:creatorは4%と3%、twitter:urlは4%と3%、twitter:domainは2%と2%、twitter:image:srcは1%、1%、 twitter:text:titleでは0%と1%、最後に twitter:app:id:iphone は0%の割合でした(デスクトップ、モバイルページとも)。twitter:siteやtwitter:imageなどのTwitterメタタグは、デスクトップサイトでより大きな存在感を示していますが、これらのメタタグの大半はモバイルとデスクトップの間、また前年比で同じ普及率を示しています。あまり一般的でないタグの中には、今年、使用率がわずかに減少したものもありますが、Twitterのメタタグの使用率は昨年から全体的に増加を維持しています。
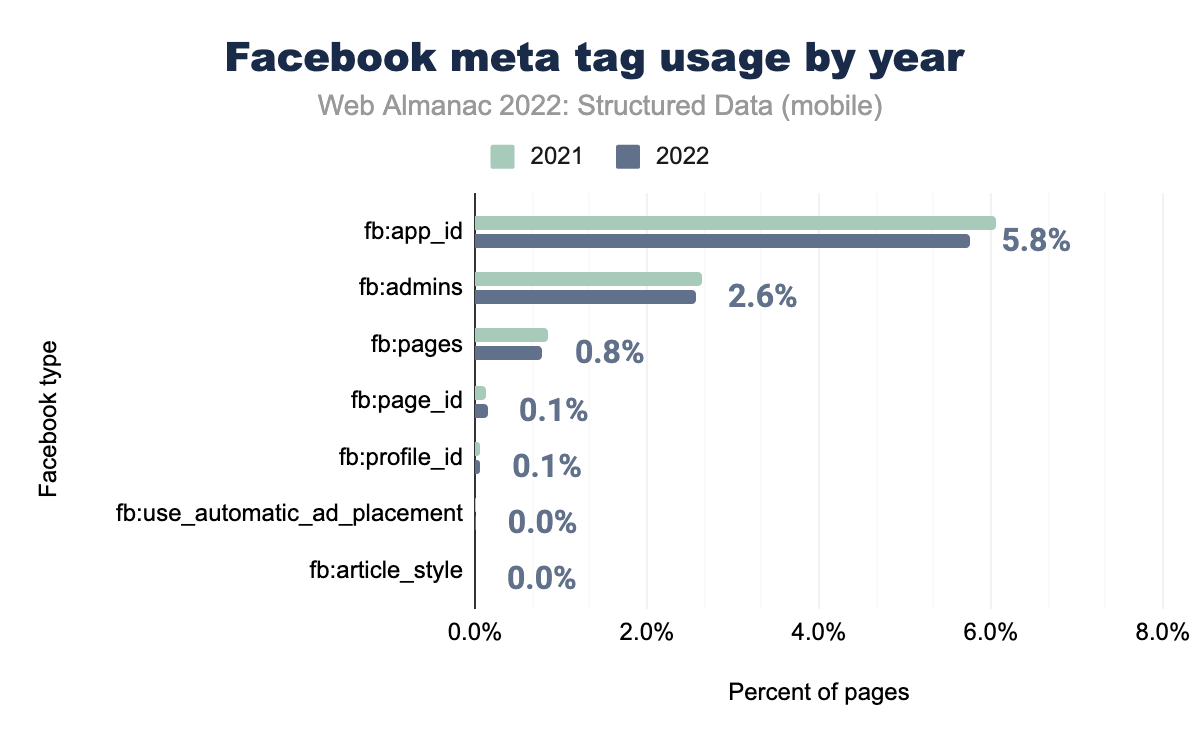
fb:app_idが使用された事を示す棒グラフ。fb:adminsはそれぞれ2.6%、2.6%、fb:pagesでは0.9%、0.8%、fb:page_idとfb:profile_id は両年で0.1%、 fb:use_automatic_ad_placementとfb:article_style は両年で0.0% となりました。ここにあるすべてのFacebookタグのうち、出現数が多いのは3つだけです。これらは2021年の上位3つと同じで、fb:app_idが5.8%、fb:adminsは2.6%、モバイルではfb:pagesが0.8%と、いずれも昨年より微減しています。
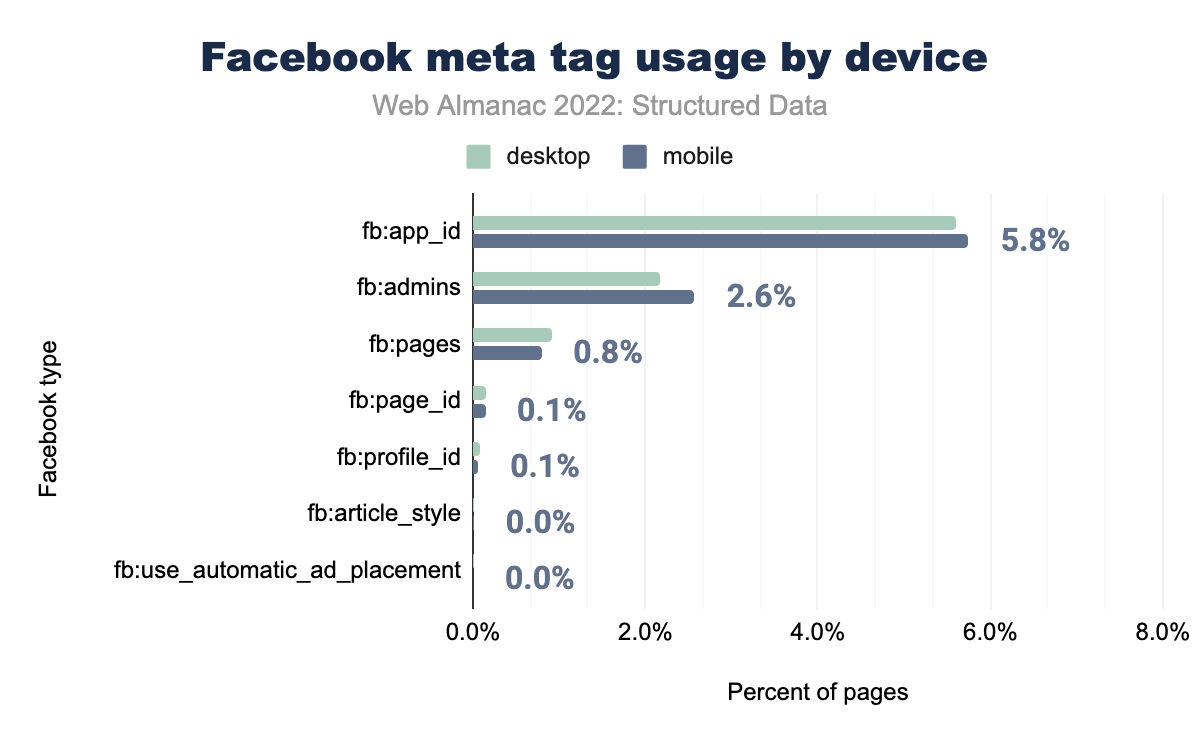
fb:app_idがデスクトップページの5.6%、モバイルページの5.8%で使用されたことを示す棒グラフです。fb:admins がそれぞれ2.2%と2.6%、 fb:pagesが0.9%と0.8%、 fb:page_idが0.2%と0.1%、 fb:profile_id がどちらも0.1% そして fb:use_automatic_ad_placementとfb:article_styleがデスクトップとモバイルページの両方で0.0% となりました。これはデスクトップページでも同様で、例外としてfb:pagesは2021年の0.90%から2022年には0.92%に微増することが分かっています。メタタグ fb:pages_id はモバイルページ、デスクトップページともに微増ですが、facebookメタタグの使用率は昨年からモバイルページ、デスクトップページともに全体として減少しています。
マイクロフォーマットとマイクロフォーマット2
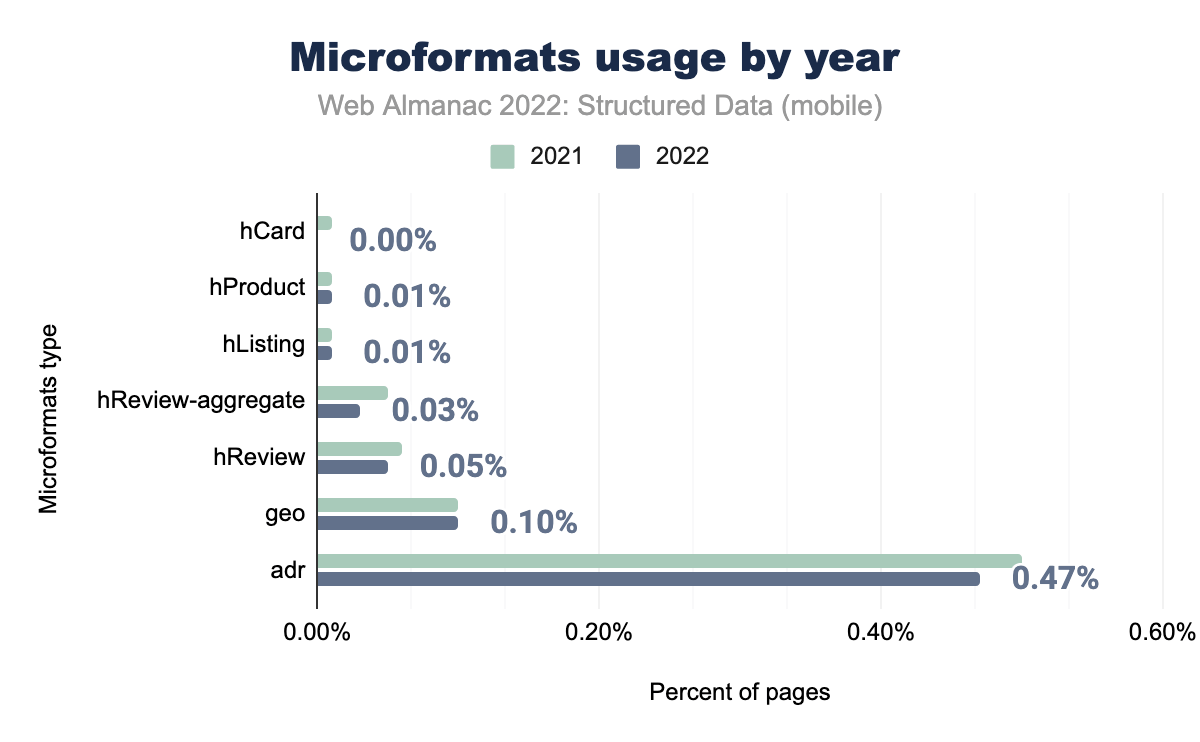
adrが使用された事を示す棒グラフ。geo がそれぞれ0.10%、0.10%、hReviewが0.06%、0.05%、hReview-aggregateは0.05%と0.03%、hListingとhProduct が両年とも0.01%、最後に hCard が2021年にはモバイルページの0.01%、2022年には0.00% で使用されます。マイクロフォーマットは、2021年以降、使用法の数はもっとも一般的なもので、adr(私たちのセットの0.47%のページに出現)は、依然としてリストの中でもっとも一般的なものです。
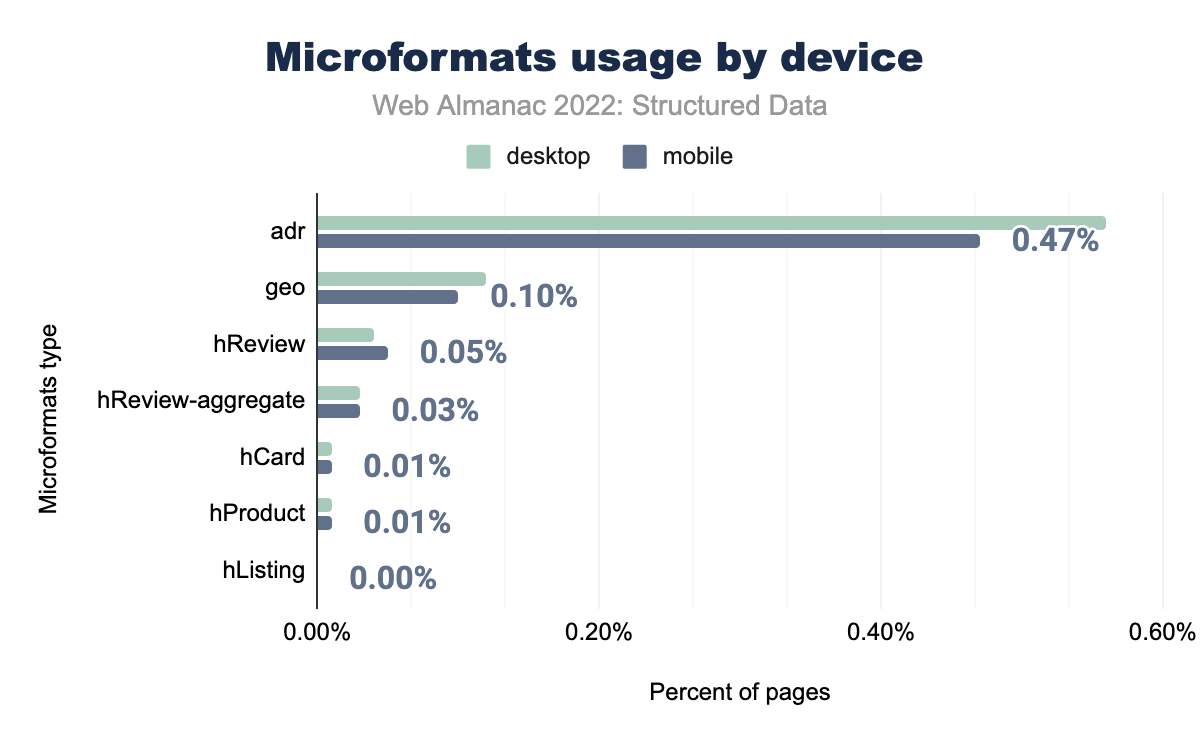
adrがデスクトップページの0.56%、モバイルページの0.47%で使用されていることを示しています。geoが0.12%と0.10% で、hReviewが0.04%と0.05% で、hReview-aggregateが0.03%と0.03%で、hListingが0.00%と0.01%、hProductが0.01%と0.01%、最後にhCard はデスクトップページの0.01% とモバイルページの0.00% で使用されています。モバイルとデスクトップともに、マイクロフォーマットの種類によって利用が増加したり減少したりしますが、どちらも平均すると昨年の数値より少なくなっています。減少の要因となったのは、hReview(モバイルページで0.06%から0.05%、デスクトップページで0.06%から0.04%)とhReview-aggregate(モバイルとデスクトップの両方で0.06%から0.04%)のタイプでした。

h-entryが使われ、0.04%と0.21%でh-cardが使われていることを示しています。h-feedは0.01%と0.18% で、h-adrは0.02%と0.02% で、h-eventは0.00%と0.00% で、h-productは0.00%と0.00%、最後に h-itemは2021年に0.01%、2022年は0.00% でモバイルページに対して使用されています。一方、2021年以降、マイクロフォーマット2の属性は急増しています。h-entry、h-card、h-feedのプロパティは、我々のページのセットで大きな増加を示しており、これはマイクロフォーマット2の属性が前年からほぼ3倍になったことを説明するものです。

h-entryがデスクトップページの0.12%、モバイルページの0.25%、h-cardがそれぞれ0.09%、0.21%、h-feedでは0.05%、0.18%、h-adrは0.02%、そして h-event, h-productとh-item がデスクトップとモバイルページの0.00%で使用されていたことを示すものです。この増加は、モバイルページでより顕著に見られますが、デスクトップページも同じパターンを辿っています。それ以外では、h-adrは両年、両プラットフォームとも0.02%でまったく変わりません。
マイクロデータ

schema.org/webpageが使用されていることを示す棒グラフです。schema.org/sitenavigationelementが5.6%と6.1%、schema.org/wpheaderが4.9%と5.3%、schema.org/wpfooterが4.6%と4.9%、schema.org/organizationが4.0%と4.3%、schema.org/blogが3.7%と3.4%、schema.org/creativeworkが2.1%と2.5%、schema.org/imageobjectが1.8%と1.9%、schema.org/personが1.4%と1.4%、schema.org/websiteが1.3%と1.4%、schema.org/postaladdressが1.3%と1.3% でありました。schema.org/blogpostingが1.3%と1.2%、schema.org/wpsidebarが1.4%と1.2%、schema.org/imagegalleryが1.1%と1.1%、schema.org/productが1.2%と1.1%、 schema.org/offerが1. 1%と1.0%、 schema.org/listitem が1.0%、1.0%、schema.org/breadcrumblistが1.0%、1.0%、そして最後に schema.org/articleが2021年にモバイルページの0.9%、2022年にモバイルページの0.8%で使用されています。マイクロデータのプロパティのほとんどはあまり変化していませんが、webpage、sitenavigationelement、wpheaderといったより一般的なプロパティは、それぞれモバイルページの7.9%、6.1%、5.3%に表示されており、若干の増加が見られます。
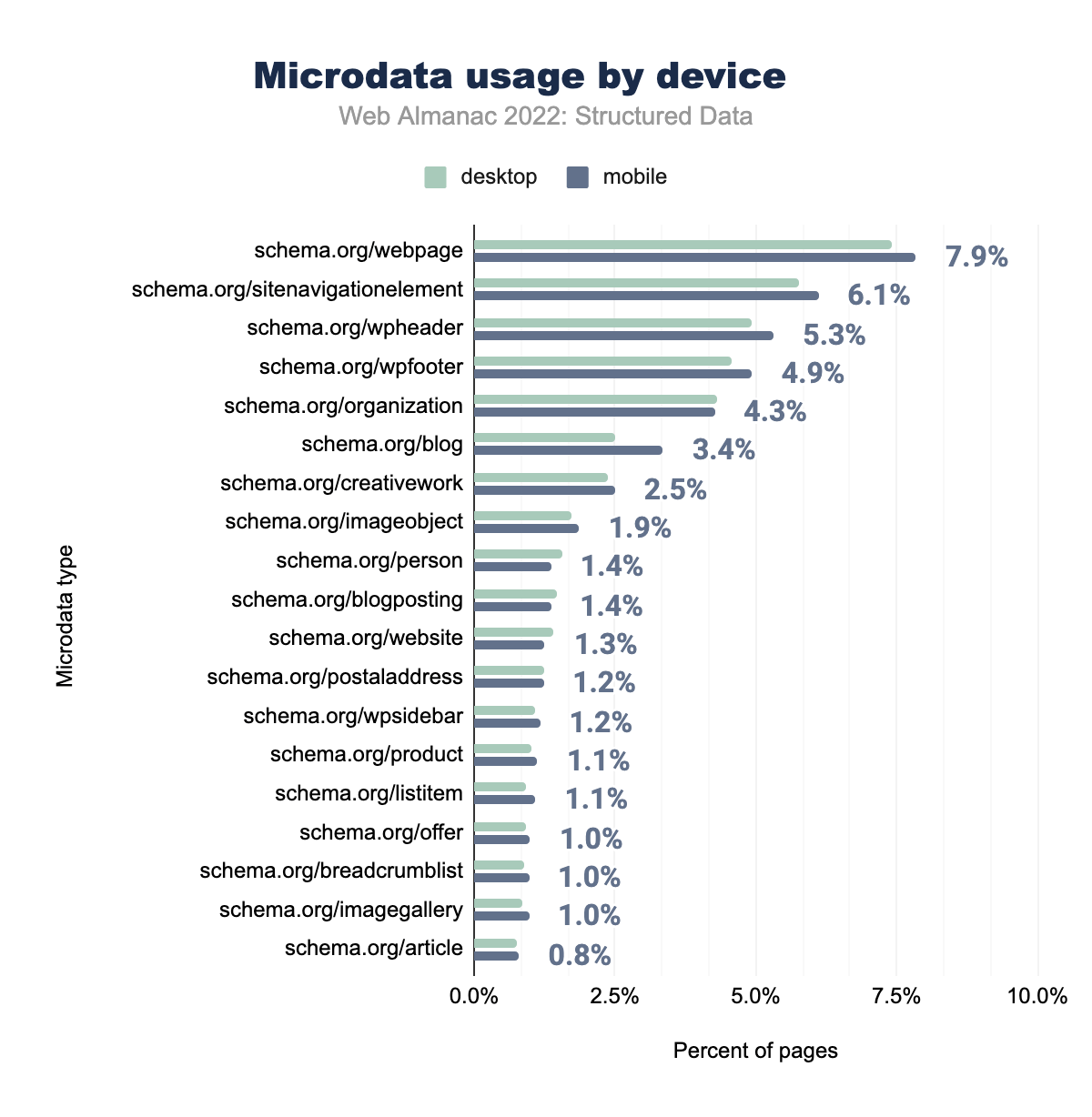
schema.org/webpageがデスクトップの7.4%、モバイルの7.9%のページで使用されていることを示しています。schema.org/sitenavigationelementが5.8%と6.1%、schema.org/wpheaderが4.9%と5.3%、schema.org/wpfooterが4.6%と4.9%、schema.org/organizationが4.3%と4.3%、schema.org/blogが2.5%と3.4%、schema.org/creativeworkが2.4%と2.5%、schema.org/imageobjectが1.7%と1.9%、schema.org/personが1.6%と1.4%、schema.org/websiteが1.4%と1.4%、schema.org/postaladdressが1.3%と1.3%、schema.org/blogpostingは1.5%と1.2%、schema.org/wpsidebarは1.1%と1.2%、schema.org/imagegalleryは0.9%と1.1%、schema.org/productは1.0%と1.1%、schema.org/offerは0.9%と1.0%、schema.org/listitemは0.9%と1.0%、schema.org/breadcrumblistは0.9%と1.0%、最後に schema.org/article はデスクトップとモバイルページの両方で0.8% 使用されています。これらの増加はデスクトップでも同様で、wpsidebar(モバイルページでは1.4%から1.2%、デスクトップページでは1.3%から1.1%)など他の場所ではわずかに減少し、モバイル、デスクトップページともに全体として過去1年間の変化は最小となっています。
JSON-LD
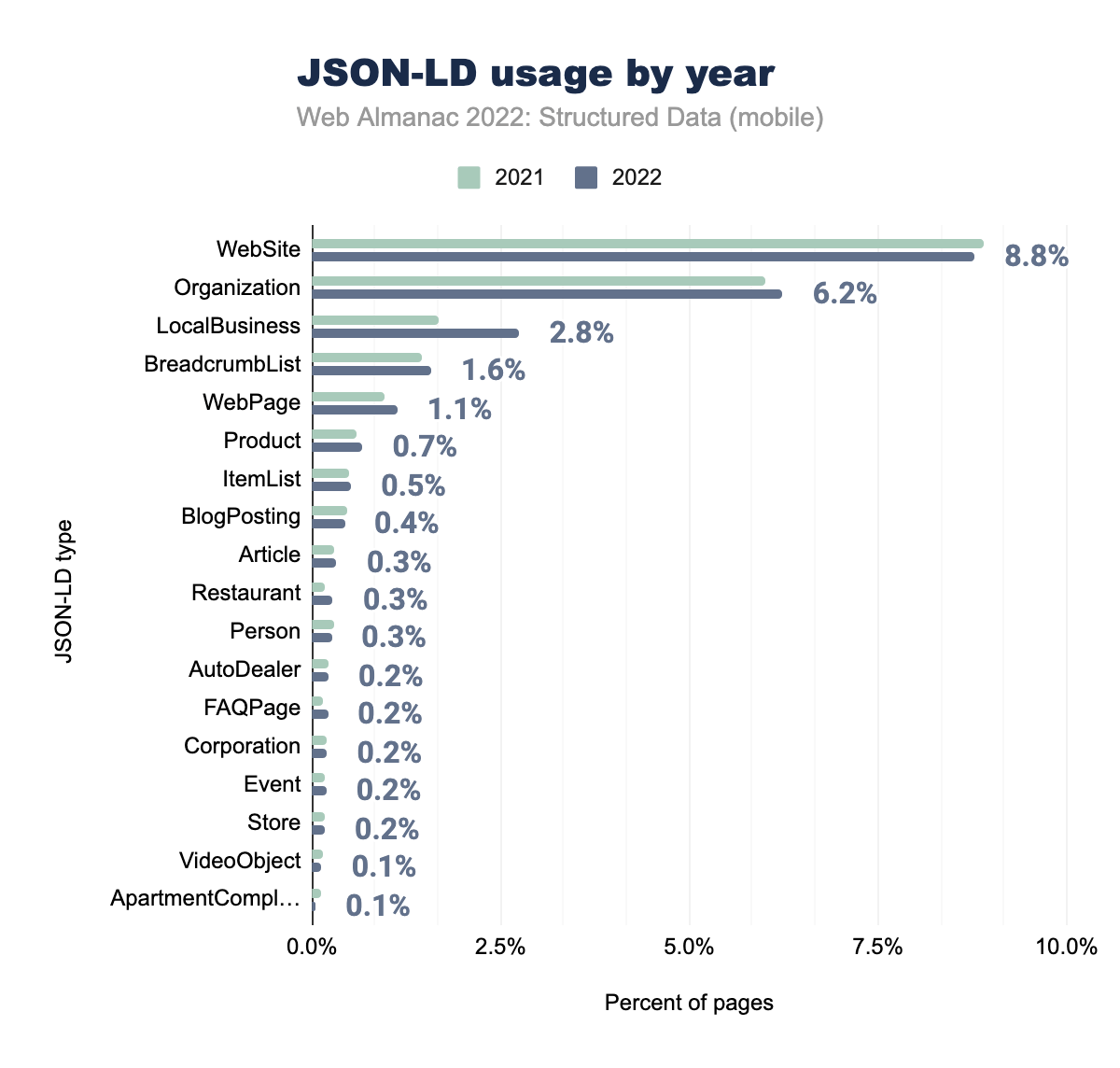
WebSiteが使用され、Organizationはそれぞれ6.0%、6.2%で使用されていることを示している。LocalBusinessが1.7%と2.8%、BreadcrumbListが1.5%と1.6%、WebPageが1.0%と1.1%、Productが0.6%と0.7%、ItemListが0.5%と0.5%、BlogPostingが0.5%と0.4%、Articleが0.3%と0.3%、Restaurantが0.2%と0.3%、Personが0.3%と0.3%、AutoDealerは0.2%と0.2%、 FAQPageは0.1%と0.2%、 Corporationは0.2%と0.2%、 Eventは0.2%と0.2%、 Storeは0.2%と0.2%、 VideoObjectは0.2%と0.1%、そして最後にApartmentComplexが2021年、2022年ともにモバイルページで0.1%となっています。JSON-LDのタイプは、前年と比較していくつかの顕著な増加があるものの、ほぼ同様の傾向が続いています。とくに、LocalBusiness(セット内のページの2.8%に増加)とRestaurant(セット内のページの0.3%に増加)が挙げられます。
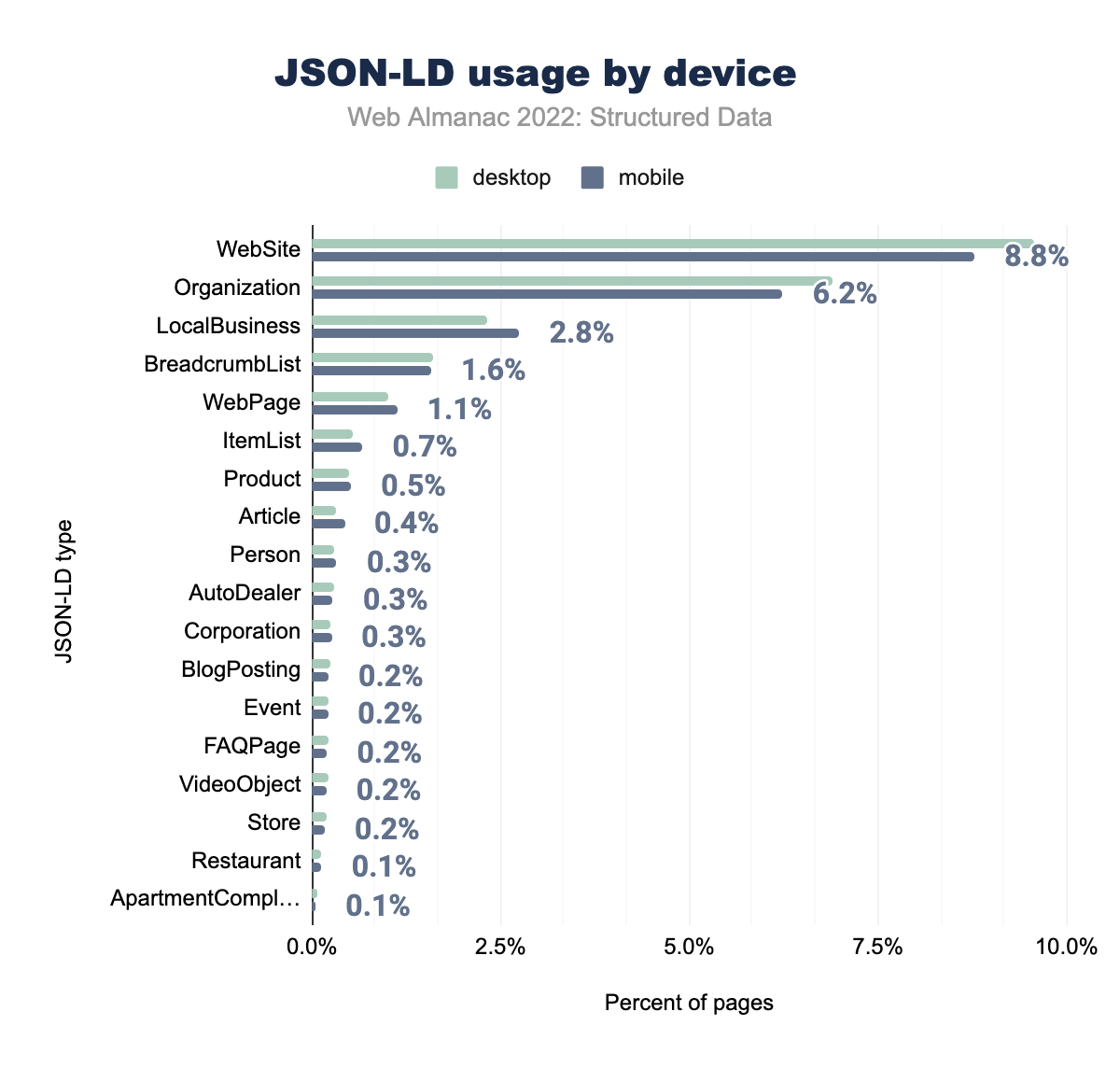
WebSiteが使用されていることを示しています。Organizationが6.9%、6.2%、LocalBusinessでは2.3%、2.8%、BreadcrumbListは1.6%と1.6%、WebPageが1.0%と1.1%、Productが0.5%と0.7%、ItemListが0.6%と0.5%、BlogPostingが0.2%と0.4%、Articleが0.3%と0.3%、Restaurantが0.1%と0.3%、Personが0.3%と0.3%、AutoDealerは0.3%と0.2%、 FAQPageは0.2%と0.2%、 Corporationは0.2%と0.2%、 Eventは0.2%と0.2%、 Storeは0.2%と0.2%、また、VideoObjectは0.2%と0.1%で、最後にApartmentComplexはデスクトップとモバイルの両方のページの0.1%で使用されています。これらの増加により、JSON-LDタイプは2021年以降で2番目に大きなポジティブな変化を遂げ、セット内のモバイルページでは33.5%から36.5%に、デスクトップページでは34.1%から36.9%に表示されています。
JSON-LDの関係
JSON-LDを評価する場合、異なるクラス間の関係でもっとも繰り返されるパターンに注目することができる。他の構文に比べて、JSON-LDは構造化されたデータのグラフの価値を表現している。たとえば、Articleは、リンクされたimageとその 著者 を表すPersonというエンティティタイプによって頻繁に特徴付けられます。同様に、 BlogPosting も画像とリンクしていますが、 Publisher として機能する Organization との関係が頻繁に見られます。
いくつかのタイプは純粋に構文的なもので、たとえば BreadcrumbList はサイトナビゲーションシステムの異なるアイテム (itemListElement) を接続するためにのみ使用され、 Question は通常その答え (acceptedAnswer) と連動しています。他の要素は意味を扱います。LocalBusinessは通常、addressと営業時間(openingHoursSpecification)にリンクされています。
この分析では、エンティティ間のもっとも一般的なタイプの関係と、たとえば ArticleとBlogPosting の微妙な違いについて、鳥瞰図的な概観を共有したいと思います。
ここでは、すべての構造体/リレーションシップの値において、どれだけ頻繁に出現するかに基づいて、異なるタイプ間の共通のリンクを見ることができます。これらの構造のいくつかは、通常、より大きなリレーションシップチェーンの一部となっています。

WebPage はもっとも大きな “From” アイテムで、複数の “Relationship” タイプと “To” 結果に分岐します (たとえば WebPage -> PotentialAction -> SearchAction)。続いてWebSite、Organization、Product、BreadCrumblist、BlogPostingと続き、徐々に他の項目が使用されるようになります。真ん中の “Relationships” カラムでは、 PotentialAction がもっともよく使われ、次に ItemListElement, IsPartOf, Publisher, image と続き、同じようにロングテールでどんどん使用頻度が減っていくことになります。”To” カラムでは、もっとも多く使われているのはImageObject で、以下はOrganization, SearchAction, ListItem, WebSite, WebPage と続き、さらに長いテールで使用頻度が減少しています。このグラフから得られる一般的な感覚は、3つの列の間で多くのクロスユースがあり、多くの異なる関係があるということです。また、ニュースやメディアからEコマース、ローカルビジネスからイベントなど、これらの構成の背景にあるバーティカル(垂直)な要素も分析されています。
以下では、同じデータを、左がソース属性、右がターゲットクラスでインタラクティブに見ることができます。

itemListElementからListItem、isPartOfからWebsite、potentialActionからSearchActionとReadAction、image、logo、primaryImageOfPage から ImageObjectで、続いてあまり使われていない長いリレーションのリストあります。この分析の主な限界は、関係性の連鎖をホームページレベルで評価できることに表されている。
SameAs
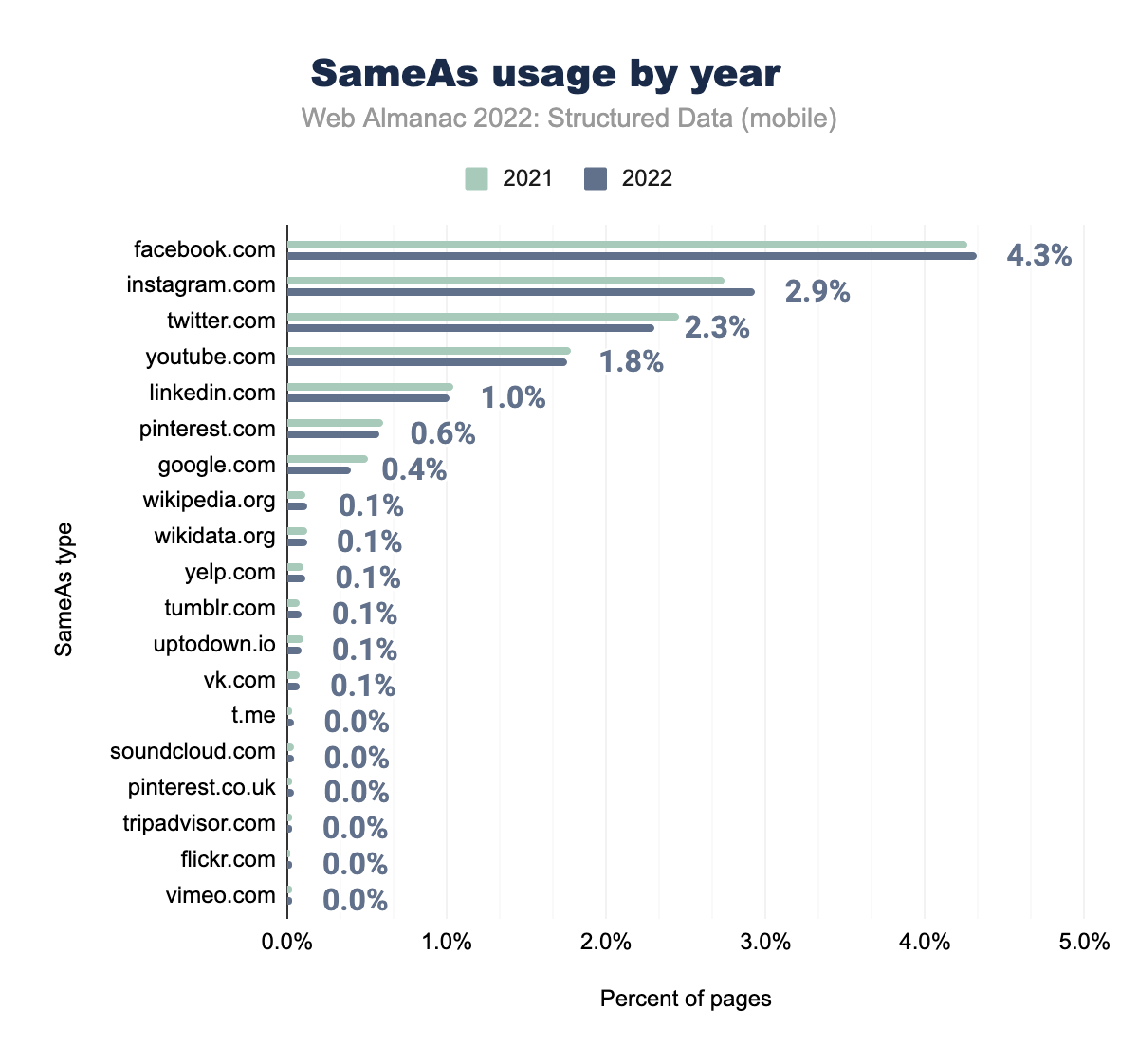
WebSiteが使用されていることを示す棒グラフ。Instagram.comが2.7%と2.9%、twitter.comが2.5%と2.3%、youtube.comが1.8%と1.8%、linkedin.comが1.0%と1.0%、 pinterest.comが0.6%と0.6%、 google.comが0.5%と0.4%、 wikipedia.orgが0.1%と0.1%、wikidata.orgが0.1%と0.1%、 yelp.comが0.1%と0.1%、 tumblr.comが0.1%と0.1%、 uptodown.iosが0.1%と0.1%、vk.comは0.1%と0.1% で、t.me, soundcloud.com, pinterest.co.jp, tripadvisor.com, flickr.com, vimeo.comは2021年と2022年の両方でモバイルページの0.0% で使用されています。SameAsモバイル利用状況
2021年と同様、sameAsプロパティのもっとも一般的な値は、ソーシャルメディア・プラットフォームです。facebook.com(モバイル:4.32%、デスクトップ:4.94%)、instagram.com(モバイル:2.93%、デスクトップ:3.34%)、twitter.com(モバイル:2.30%、デスクトップ:2.86%)などであった。前2者は2021年からモバイルでやや増加し、3者ともデスクトップで増加している。

facebook.comがデスクトップの4.9%、モバイルの4.3%、instagram.comが3.3%、2.3%、twitter.comは2.9%、1.8%、youtube.comが1.4%と1%、pinterest.comが0.7%と0.6%、goo.comが0.5%と0.4%、wikipedia.orgは0.1%、0.1%、 wikidata.org が0.1%、0.1%、 yelp.comが0.1%、0.1%、 tumblr.comでは0.1%と0.1%、 uptodown.io が0.1%、 0.1%、 vk.comが0.1%と0.1% 、そして t.me、soundcloud.com、pinterest.co.uk、tripadvisor.com、flickr.com、そして vimeo.com がデスクトップとモバイル両方のページの0.0%で使用されていることがわかりました。SameAs の使用状況
残りのリストには、wikipedia.org(モバイル、デスクトップともに0.13%)、yelp.com(モバイル0.11%、デスクトップ0.13%)などの情報源が含まれており、いずれも前年より増加しています。
JSON-LDのさらなる洞察 - 相対的な変化
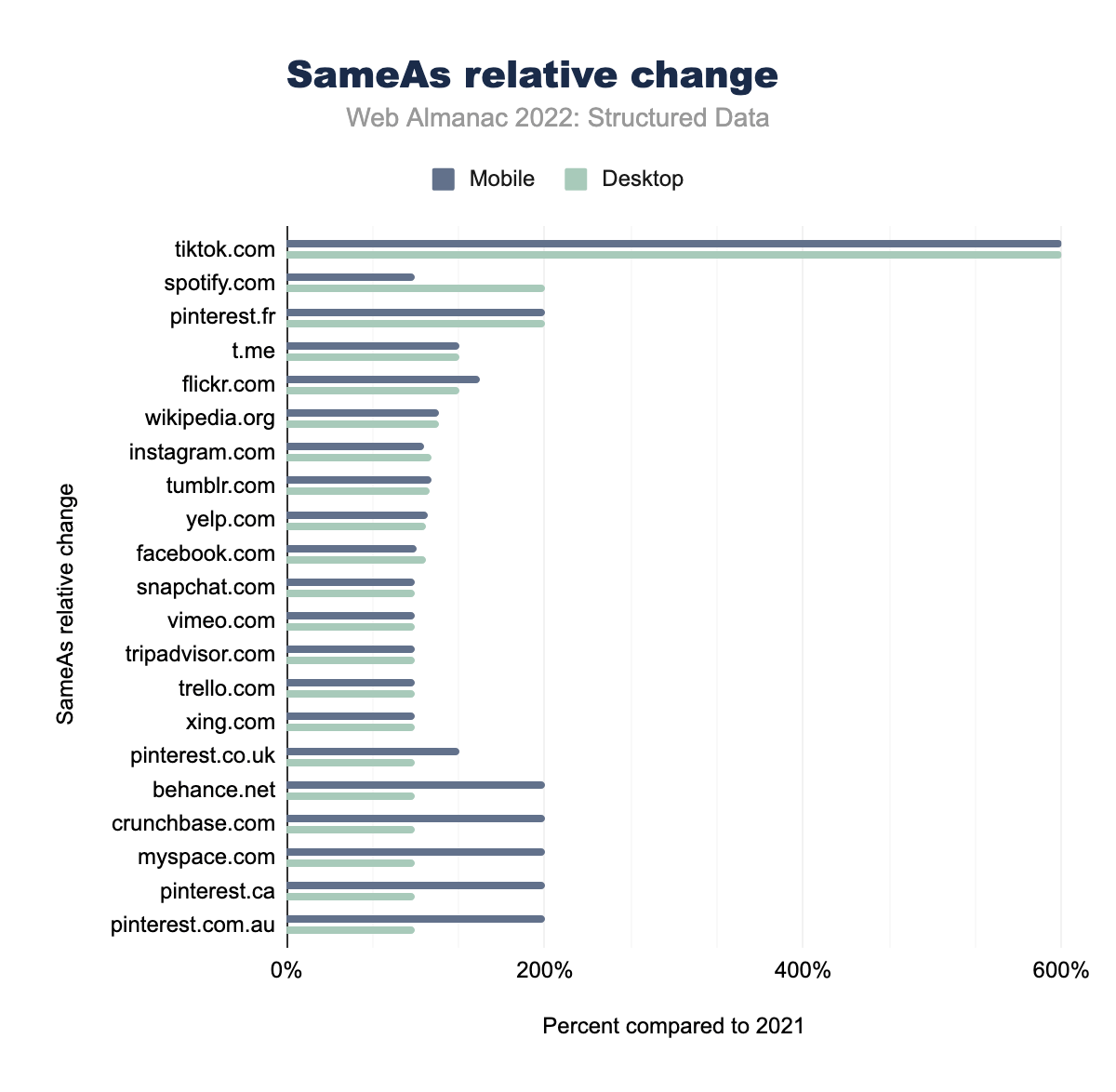
tiktok.comがデスクトップとモバイルの両方のページで600%変化し、spotify.comがデスクトップで100.00%、モバイルは200.00%、 pinterest.fr がそれぞれ200.00%と200.00%、 t.meが133.33%と133.33%、 flickr.comが150%と133.33%、 wikipedia.orgが118.18%と118.18%、 instagram.comが106.93%と112.46%、 tumblr.comが112.50%と111.11%、 yelp.comが110.00%と108.33%、facebook.comが101.41%と107.39%、snapchat.comが100.00%と100.00%、vimeo.comが100.00%と100%、tripadvisor.comが100.00%と100%、trello.comが100.00%と100%、xing.comが100%と100.00%、pinterest.co.ukは133.33%と100.00%、 behance.net, crunchbase.com, myspace.com, pinterest.ca, pinterest.com.au はデスクトップでは200.00% 、モバイルでは100.00% で変化しています。SameAs相対的変化量
また、SameAsの項目とその経時的な変化も興味深い。TikTokは、2021年と比較して、2022年は6倍ものページで表示され、大幅な増加を示しています。この変化は、デスクトップとモバイルの両方のページで同じです。Pinterestとそのドメイン名は、2022年にモバイルページでもっとも多く増加した上位5つのうち3つを占めています。モバイル全体では、デスクトップよりもSameAsエントリーの増加が大きいですが、Spotifyは例外で、デスクトップページの出現数が2021年と比較して2倍になっています。

frがデスクトップとモバイルの両方のページで200%変化し、siteがデスクトップで200.00%、モバイルは100.00%、deがそれぞれ200%と100%、comが125%と118%、meが117%と117%、orgが103%と106%、netが100%と200%、caが100%と200%、coが100%と117%、最後にit, page および es が100%となった状態を示している。SameAs平均相対変化量
また、SameAsエントリーのドメイン名と、そのドメイン名が時間とともにどのように変化するかを見ることで、貴重な洞察を得ることができるかもしれません。デスクトップページの増加数がもっとも多いのは、.ca、.net、.frで、後者はモバイルページの増加数でも上位にランクインしています。これは平均値であるため、エントリーの量は考慮されていません。どちらの年も、.comは他のすべてのエントリよりも数が圧倒的に多いのですが、平均の変化はモバイルページで125%、デスクトップページで117%となっています。カナダとフランス語のドメインの平均は、前述のように昨年から広く増加しているPinterestによって大きく押し上げられています。もっとも多いSameAsドメイン上位10個のうち7個がPinterestを利用しており、時にはそれが唯一の利用例となることもあります。
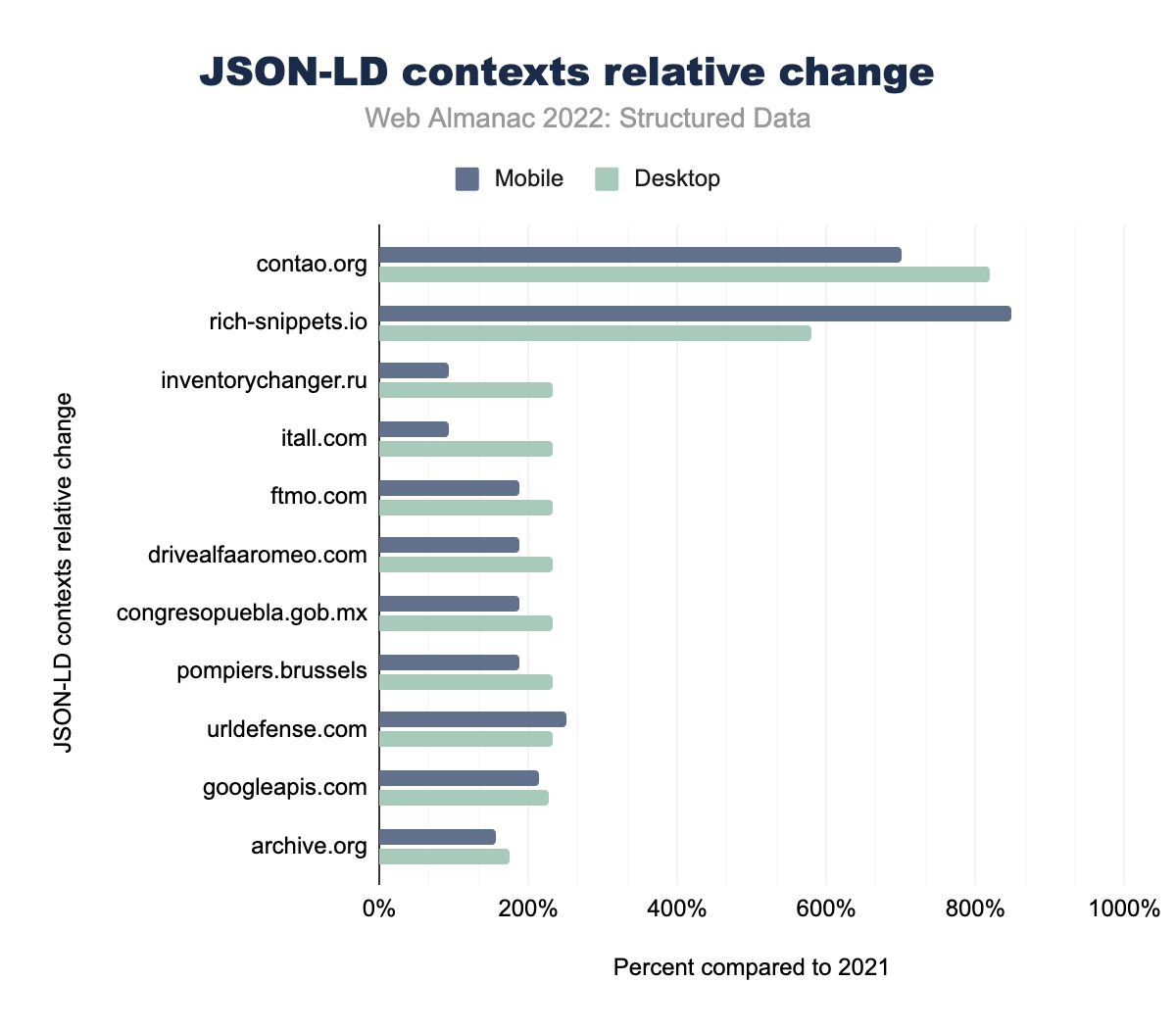
contao.org がデスクトップで819%、モバイルは701%、 rich-snippets.ioが579%、849%、inventorychanger.ruは232%、94%、itall.comが232%、94%、ftmo.comで232%、189%、 drivealfaaromeo.comが233%、189%、congresopuebla.gob.mx232%、189%、 pompiers.brussels 232%と189%、 urldefense.com232%、252%、 googleapis.com227%と214%、最後にarchive.org ではデスクトップが174%、モバイルは157%増加していることが確認されました。JSON-LDコンテキストについては、schema.orgが圧倒的に貢献度が高く、デスクトップページでは6,000倍以上、モバイルページでは2位のgoogleapis.comの3,500倍以上の登場回数となっています。とはいえ、schema.orgが昨年の108%という控えめな増加率だったのに比べ、googleapis.comの出現数はデスクトップとモバイルページの両方で2倍以上になっています。トップグロワーを見ると、contao.orgとrich-snippets.ioがトップで、contao.orgのデスクトップページの増加率は819%、 rich-snippets.ioのモバイルページの増加率は849% です。Contao.orgは総エントリー数で4位、rich-snippets.ioは8位にランクインしています。
結論
構造化データがウェブに、ひいては私たちの体験にどのような影響を与えるかについて、多くの概説がなされてきました。今年は、構造化データの採用が1年間でどのように変化したかを比較することにも焦点を当てました。たとえば、LocalBusiness(とくにレストラン)やFAQのようなクラスが全般的に増加し、foafやマイクロデータ構文に由来するあまり関連性のない構造化データ型の利用がわずかに減少していることがわかります。
包括的なリストとは言いがたいが、構造化(リンク)されたデータは、いくつかの利点をもたらすと考えられる。
- Eコマースページ
- ビジネスページ
- 研究者紹介
- ソーシャルメディアサイト
- ユーザー
SEOを通じて、発見力の向上、一般的なデータのリンク、リッチな結果が採用を後押しする。ウェブページにセマンティックマークアップを実装することで、よりつながりやすく、アクセスしやすいウェブが実現します。
これまで以上に多くの情報と洞察が得られるようになった現在、ウェブページのトラフィックを増やそうとする場合、特定のテクニックや選択肢の能力と限界を理解することが不可欠です。SEOを向上させる目的で偽のレビューや誤解を招くデータを追加すると検出され、その結果、上記のようなメリットが少なくなり、検索エンジンからの検出性とパフォーマンスが低下します。
前年度にすでに述べたように、SEOが構造化データ導入の重要な推進力であることに変わりはありませんが、検索エンジン以外の使用事例が増えつつあります。ウェブサイトの所有者はシステムの相互運用性を高め、コンテンツ推薦システムを訓練し、ウェブページから新しい洞察を得るために、さまざまなシナリオでデータを追加しています。
Web Almanacのこの章はまだ2年目ですが、これらのトレンドがどのように継続し変化していくのか、またWebにおける構造化データの状態も含めて、私たちは楽しみにしています。構造化データがもたらすあらゆる利点から、これらの技術の導入が進むことを期待しています。

