Marcado Web
Introduction
En 2005, Ian “Hixie” Hickson publicó algunos análisis de datos de marcado basándose en varios trabajos anteriores. Gran parte de este trabajo tenía como objetivo investigar los nombres de las clases para ver si había una semántica informal común que los desarrolladores estaban adoptando y que podría tener sentido estandarizar. Parte de esta investigación ayudó a darle forma a nuevos elementos en HTML5.
14 años después, es hora de dar un nuevo vistazo. Desde entonces, hemos tenido la introducción de Elementos Personalizados y del Manifesto Web Extensible alentando a que encontremos mejores formas de pavimentar los caminos de acceso al permitir a los desarrolladores explorar el espacio de los elementos y permitir a los organismos de estándares actuar más como editores de diccionario. A diferencia de los nombres de clase CSS, que podrían usarse para cualquier cosa, podemos estar mucho más seguros de que los autores que usaron un elemento no estándar realmente pretendían que fuera un elemento.
A partir de julio de 2019, el HTTP Archive ha comenzado a recopilar todos los nombres de elementos usados en el DOM para aproximadamente 4,4 millones de páginas de inicio de computadoras de escritorio y alrededor de 5,3 millones de páginas de inicio de dispositivos móviles que ahora podemos comenzar a investigar y diseccionar. (Conozca más sobre nuestra Metodología.)
Esta exploración encontró más de 5.000 nombres distintos de elementos no estándar en estas páginas, por lo que limitamos el número total de elementos distintos que contamos a los ’principales’ (explicado a continuación) 5.048.
Metodología
Los nombres de los elementos en cada página se recopilaron del DOM mismo, después de la ejecución inicial de JavaScript.
Mirar un recuento de frecuencia sin procesar no es especialmente útil, incluso para elementos estándar: Alrededor del 25% de todos los elementos encontrados son <div>. Alrededor del 17% son <a>, alrededor del 11% son <span> -- y esos son los únicos elementos que representan más del 10% de las ocurrencias. Los lenguajes generalmente son así; un pequeño número de términos se usan asombrosamente en comparación. Además, cuando comenzamos a buscar elementos no estándar para la captación, esto podría ser muy engañoso, ya que un sitio podría usar un cierto elemento miles de veces y, por lo tanto, parecer artificialmente muy popular.
En lugar, como en el estudio original de Hixie, Lo que veremos es cuántos sitios incluyen cada elemento al menos una vez en su página de inicio.
Principales elementos e información general
En 2005, la encuesta de Hixie enumeró los elementos más comunes utilizados en las páginas. Los 3 principales fueron html, head y body lo que señaló como interesante porque son opcionales y creados por el parser si se omiten. Dado que utilizamos el DOM después del parseo , aparecerán universalmente en nuestros datos. Por lo tanto, comenzaremos con el cuarto elemento más utilizado. A continuación se muestra una comparación de los datos de entonces a ahora. (También he incluido la comparación de frecuencias aquí solo por diversión).
| 2005 (por sitio) | 2019 (por sitio) | 2019 (frecuencia) |
|---|---|---|
| title | title | div |
| a | meta | a |
| img | a | span |
| meta | div | li |
| br | link | img |
| table | script | script |
| td | img | p |
| tr | span | option |
Elementos por página
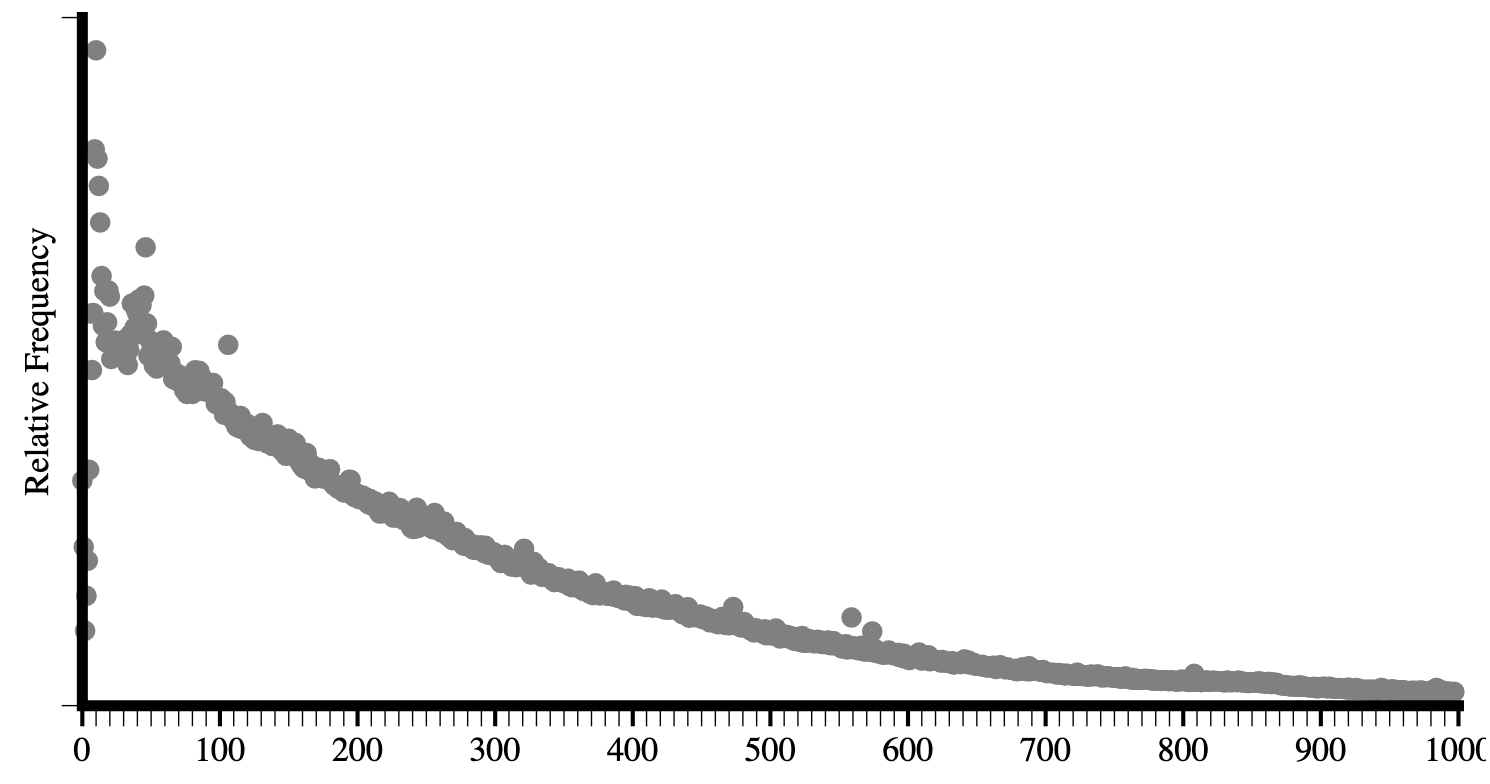
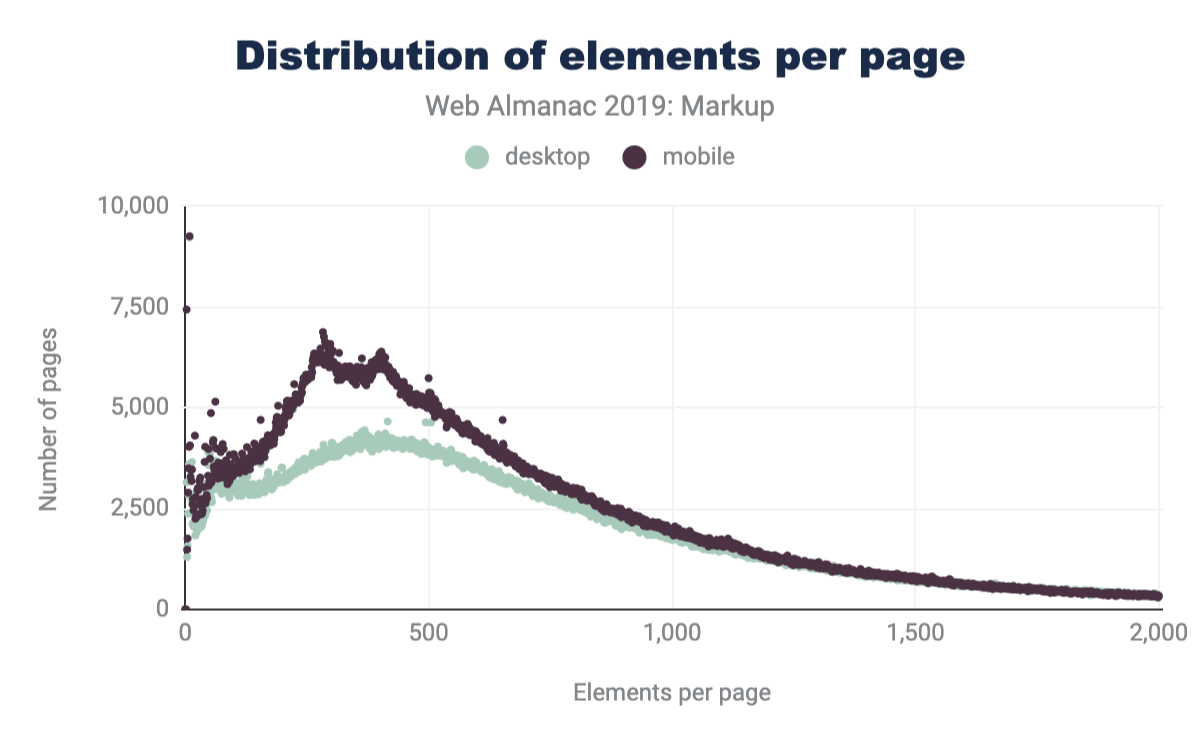
Comparando los últimos datos en la Figura 3.3 con los del informe de Hixie de 2005 en la Figura 3.2, podemos ver que el tamaño promedio de los árboles DOM ha aumentado.
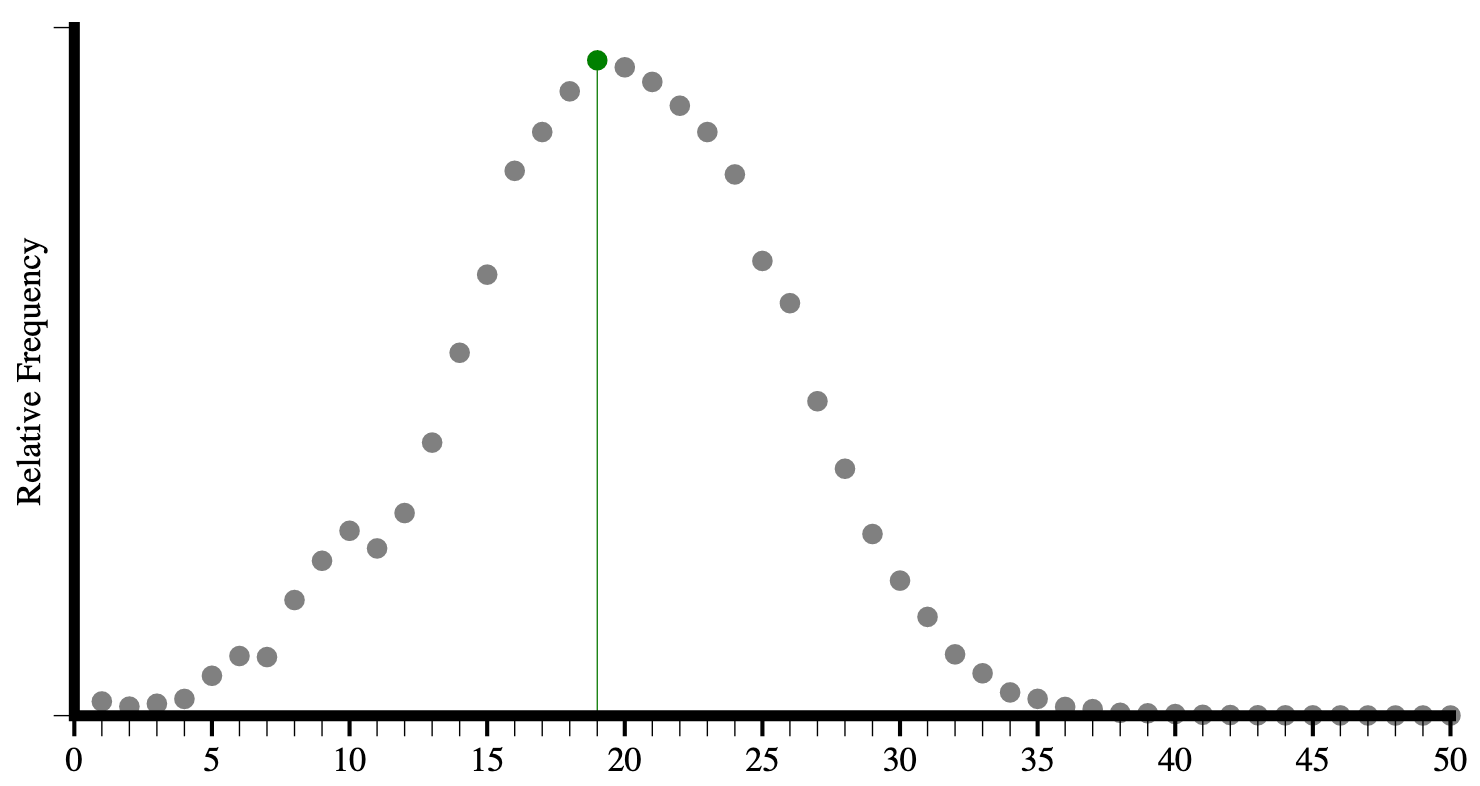
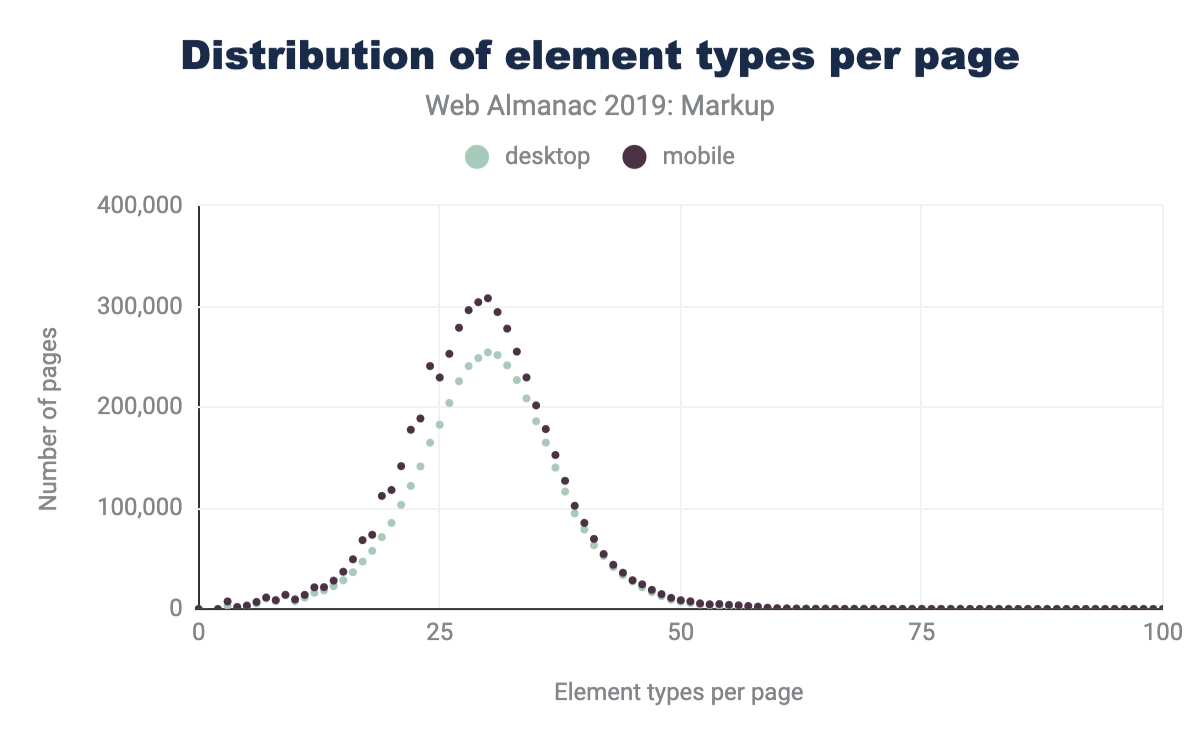
Podemos ver que tanto el número promedio de tipos de elementos por página ha aumentado, como el número máximo de elementos únicos que encontramos.
Elementos personalizados
La mayoría de los elementos que grabamos son personalizados (como en simplemente “no estándar”), pero discutir qué elementos son y no son personalizados puede ser un poco difícil. Escrito en alguna especificación o propuesta en algún lugar hay, en realidad, bastantes elementos. Para fines aquí, consideramos 244 elementos como estándar (aunque algunos de ellos están en desuso o no son compatibles):
- 145 Elementos de HTML
- 68 Elementos de SVG
- 31 Elementos de MathML
En la práctica, encontramos solo 214 de estos:
- 137 de HTML
- 54 de SVG
- 23 de MathML
En el conjunto de datos de escritorio, recopilamos datos para los principales 4,834 elementos no estándar que encontramos. De estos:
- 155 (3%) son identificables como muy probable marcado o errores de escape (contienen caracteres en el nombre de la etiqueta analizada, lo que implica que el marcado está roto)
- 341 (7%) usan espacios de nombre de dos puntos al estilo XML (aunque, como HTML, no usan espacios de nombres XML reales)
- 3,207 (66%) son nombres de elementos personalizados válidos
- 1,211 (25%) se encuentran en el espacio de nombres global (no estándar, sin guión ni dos puntos)
- 216 de estos los hemos marcado como probables errores tipográficos, ya que tienen más de 2 caracteres y tienen una distancia de Levenshtein de 1 desde algún nombre de elemento estándar como
<cript>,<spsn>or<artice>. Algunos de estos (como<jdiv>), sin embargo, son ciertamente intencionales.
Además, el 15% de las páginas de escritorio y el 16% de las páginas móviles contienen elementos obsoletos.
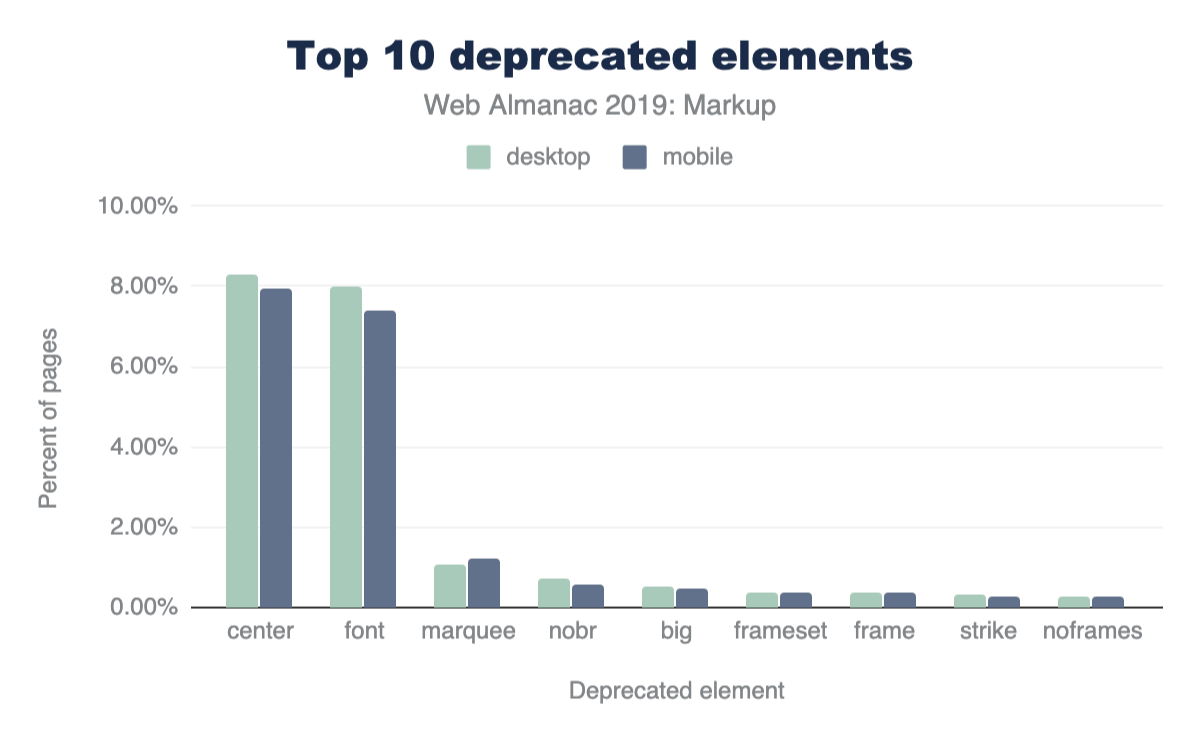
La Figura 3.6 anterior muestra los 10 elementos obsoletos más utilizados. La mayoría de estos pueden parecer números muy pequeños, pero la perspectiva es importante.
Perspectiva sobre valor y uso
Para discutir números sobre el uso de elementos (estándar, obsoleto o personalizado), primero necesitamos establecer alguna perspectiva.
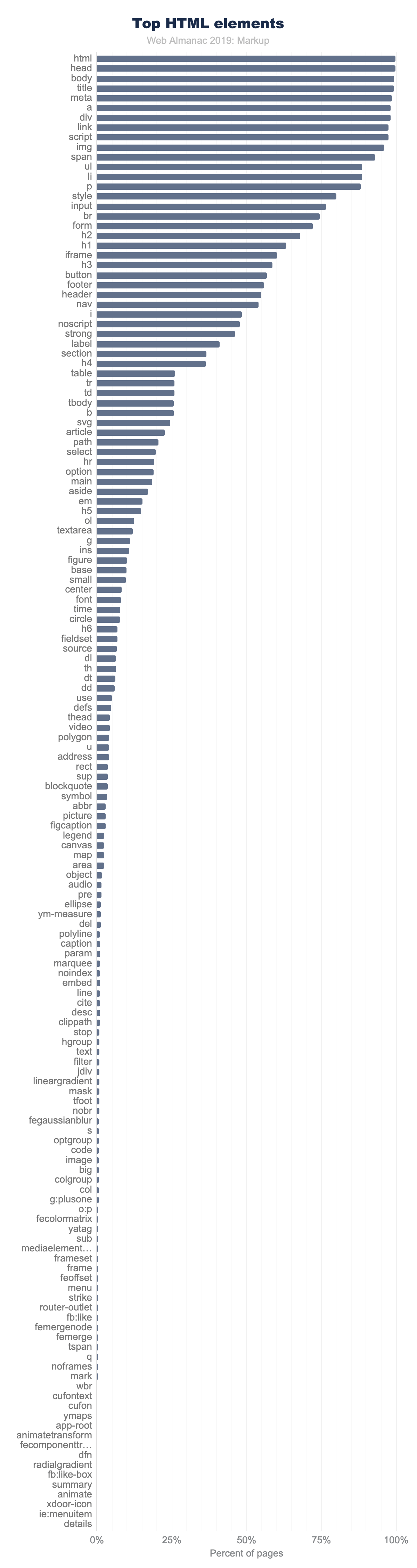
En la Figura 3.7 anterior, se muestran los 150 nombres de elementos principales, contando el número de páginas donde aparecen. Observe lo rápido que se cae el uso.
Solo se utilizan 11 elementos en más del 90% de las páginas:
<html><head><body><title><meta><a><div><link><script><img><span>
Solo hay otros 15 elementos que ocurren en más del 50% de las páginas:
<ul><li><p><style><input><br><form><h2><h1><iframe><h3><button><footer><header><nav>
Y solo hay otros 40 elementos que ocurren en más del 5% de las páginas.
Incluso <video>, por ejemplo, no cumple con el corte. Aparece solo en el 4% de las páginas de escritorio en el conjunto de datos (3% en dispositivos móviles). Si bien estos números suenan muy bajos, el 4% es en realidad bastante popular en comparación. De hecho, solo 98 elementos ocurren en más del 1% de las páginas.
Es interesante, entonces, ver cómo se ve la distribución de estos elementos y cuáles tienen más del 1% de uso.
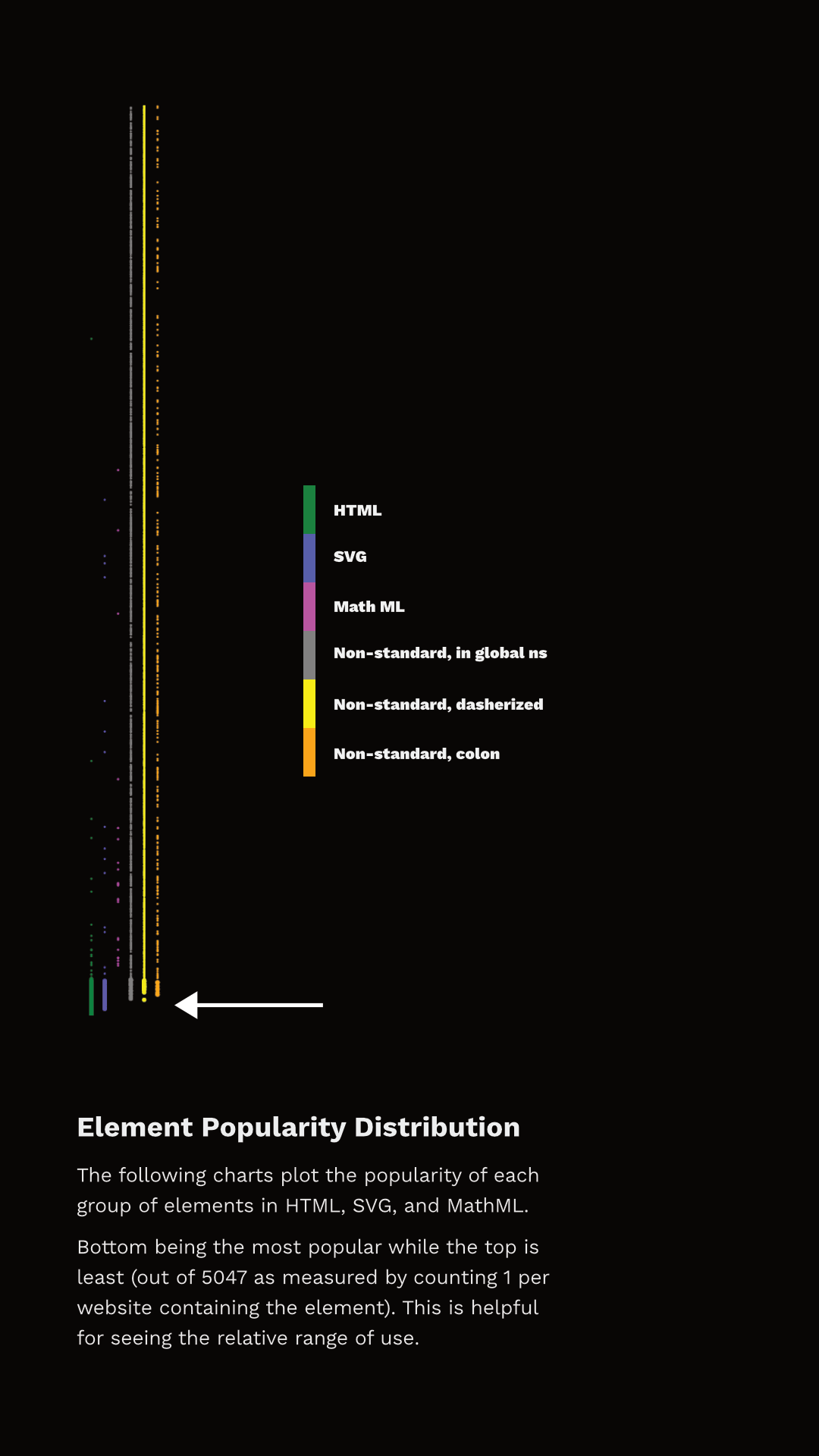
La Figura 3.8 muestra el rango de cada elemento y en qué categoría se encuentran. He separado los puntos de datos en conjuntos discretos simplemente para que puedan verse (de lo contrario, no hay suficientes píxeles para capturar todos esos datos), pero representan una única “línea” de popularidad; el más bajo es el más común, el más alto es el menos común. La flecha apunta al final de los elementos que aparecen en más del 1% de las páginas.
Se pueden observar dos cosas aquí. Primero, el conjunto de elementos que tienen más del 1% de uso no son exclusivamente HTML. De hecho, 27 de los 100 elementos más populares ni siquiera son HTML - son SVG! Y hay etiquetas no estándar en o muy cerca de ese límite también! Segundo, tenga en cuenta que menos del 1% de las páginas utilizan una gran cantidad de elementos HTML.
Entonces, ¿todos esos elementos que son utilizados por menos del 1% de las páginas “inútiles”? Definitivamente no. Por eso es importante establecer una perspectiva. Hay alrededor dos mil millones de sitios web en la web. Si algo aparece en el 0.1% de todos los sitios web de nuestro conjunto de datos, podemos extrapolar que esto representa quizás dos milliones de sitios web en toda la web. Incluso 0,01% se extrapola a doscientos mil sitios. Esta es también la razón por la cual eliminar el soporte para elementos, incluso aquellos muy antiguos que creemos que no son buenas ideas, es algo muy raro. Romper cientos de miles o millones de sitios simplemente no es algo que los proveedores de navegadores puedan hacer a la ligera.
Muchos elementos, incluso los nativos, aparecen en menos del 1% de las páginas y siguen siendo muy importantes y exitosos. <code>, por ejemplo, es un elemento que uso y encuentro mucho. Definitivamente es útil e importante, y sin embargo, se usa solo en el 0,57% de estas páginas. Parte de esto está sesgado según lo que estamos midiendo; las páginas de inicio son generalmente menos probable para incluir ciertos tipos de cosas (como <code> por ejemplo). Las páginas de inicio tienen un propósito menos general que, por ejemplo, encabezados, párrafos, enlaces y listas. Sin embargo, los datos son generalmente útiles.
También recopilamos información sobre qué páginas contenían un autor definido (no nativo) .shadowRoot. Alrededor del 0,22% de las páginas de escritorio y el 0,15% de las páginas móviles tenían un shadow root. Esto puede no parecer mucho, pero es más o menos 6.500 sitios en el conjunto de datos móviles y 10.000 sitios en el escritorio y es más que varios elementos HTML. <summary> por ejemplo, tiene un uso equivalente en el escritorio y es el elemento número 146 más popular. <datalist> aparece en el 0,04% de las páginas de inicio y es el elemento 201 más popular.
De hecho, más del 15% de los elementos que contamos según lo definido por HTML están fuera de los 200 primeros en el conjunto de datos de escritorio. <meter> es el elemento menos popular de la “era HTML5”, que podemos definir como 2004-2011, antes de que HTML se moviera a un modelo de Living Standard. Es alrededor del elemento número 1.000 en popularidad. <slot>, el elemento introducido más recientemente (abril de 2016) está situado alrededor del puesto 1.400 en cuanto a popularidad.
Muchos datos: DOM real en la web real
Con esta perspectiva en mente acerca de cómo se ve el uso de características nativas / estándar en el conjunto de datos, hablemos de las cosas no estándar.
Puede esperar que muchos de los elementos que medimos se usen solo en una sola página web, pero de hecho, todos los 5.048 elementos aparecen en más de una página. La menor cantidad de páginas en las que aparece un elemento de nuestro conjunto de datos es 15. Aproximadamente una quinta parte de ellas ocurre en más de 100 páginas. Alrededor del 7% se produce en más de 1.000 páginas.
Para ayudar a analizar los datos, hackee en conjunto una pequeña herramienta con Glitch. Puede usar esta herramienta usted mismo y por favor comparta un enlace permanente con el @HTTPArchive junto con sus observaciones. (Tommy Hodgins también ha construido una herramienta similar CLI Tool que se puede usar para explorar.)
Veamos algunos datos.
Productos (y librerías) y su marcado personalizado
Para varios elementos no estándar, su prevalencia puede tener más que ver con su inclusión en herramientas populares de terceros que la adopción por parte de primeros. Por ejemplo, el elemento <fb:like> se encuentra en el 0,3% de las páginas no porque los propietarios del sitio lo escriban explícitamente sino porque incluyen el widget de Facebook. Muchos de los elementos que Hixie mencionó hace 14 años parece haber disminuido, pero otros siguen siendo bastante grandes:
-
Elementos populares creados por Claris Home Page (cuya última versión estable fue hace 21 años) todavía aparece en más de 100 páginas.
<x-claris-window>, por ejemplo, aparece en 130 páginas. -
Algunos de los
<actinic:*>elementos del proveedor de comercio electrónico británico Oxatis aparecen en incluso más páginas. Por ejemplo,<actinic:basehref>todavía aparece en 154 páginas en los datos del escritorio. -
Los elementos de Macromedia parecen haber desaparecido en gran medida. Solo un elemento,
<mm:endlock>, aparece en nuestra lista y en solo 22 páginas. -
El elemento de Adobe Go-Live
<csscriptdict>todavía aparece en 640 páginas en el escritorio dataset. -
El elemento de Microsoft Office
<o:p>El elemento todavía aparece en el 0,5% de las páginas de escritorio, más de 20.000 páginas.
Pero hay muchos recién llegados que tampoco estaban en el informe original de Hixie, y con números aún mayores.
-
<ym-measure>es una etiqueta inyectada por Yandex del paquete de analisis Metrica. Se utiliza en más del 1% de las páginas de escritorio y móviles, consolidando su lugar en los 100 elementos más utilizados. ¡Eso es enorme! -
<g:plusone>del ahora desaparecido Google Plus se produce en más de 21.000 páginas. -
Facebook
<fb:like>ocurre en 14.000 páginas móviles. -
De manera similar,
<fb:like-box>ocurre en 7.800 páginas móviles. -
<app-root>, que generalmente se incluye en frameworks como Angular, aparece en algo más de 8.200 páginas móviles.
Comparemos esto con algunos de los elementos HTML nativos que están por debajo de la barra del 5%, por perspectiva.
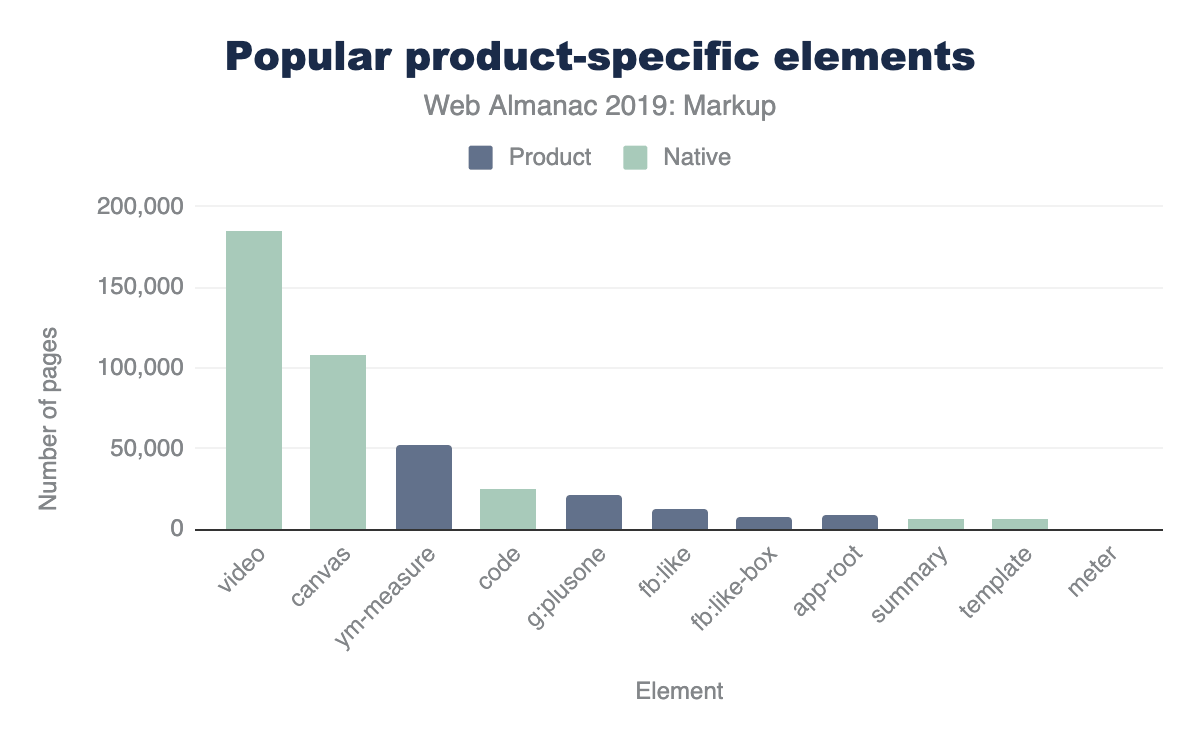
Usted podría descubrir ideas interesantes como estas durante todo el día.
Aquí hay una que es un poco diferente: los elementos populares pueden ser causados por errores directos en los productos. Por ejemplo, <pclass="ddc-font-size-large"> ocurre en más de 1,000 sitios. Esto fue gracias a la falta de espacio en un popular tipo de producto “como servicio”. Afortunadamente, informamos este error durante nuestra investigación y se solucionó rápidamente.
En su artículo original, Hixie menciona que:
Lo bueno, si se nos puede perdonar por tratar de seguir siendo optimistas ante todo este marcado no estándar, es que al menos estos elementos están claramente usando nombres específicos del proveedor. Esto reduce enormemente la probabilidad de que los organismos de normalización inventen elementos y atributos que entren en conflicto con cualquiera de ellos.
Sin embargo, como se mencionó anteriormente, esto no es universal. Más del 25% de los elementos no estándar que capturamos no utilizan ningún tipo de estrategia de espacio de nombres para evitar contaminar el espacio de nombres global. Por ejemplo, aquí está una lista de 1.157 elementos como ese del conjunto de datos móviles. Es probable que muchos de ellos no sean problemáticos, ya que tienen nombres oscuros, faltas de ortografía, etc. Pero al menos algunos probablemente presentan algunos desafíos. Se puede notar, por ejemplo, que <toast> (el cual Googlers recientemente intentaron proponer como <std-toast>) aparece en esta lista.
Hay algunos elementos populares que probablemente no sean tan desafiantes:
-
<ymaps>de Yahoo Maps aparece en ~12.500 páginas móviles. -
<cufon>and<cufontext>de una biblioteca de reemplazo de fuentes de 2008, aparece en ~10.500 páginas móviles. -
El elemento
<jdiv>, que parece estar inyectado por el producto JivoChat, aparece en ~40.300 páginas móviles.
Colocar estos elementos en nuestro mismo cuadro anterior para obtener una perspectiva se parece a esto (nuevamente, varía ligeramente según el conjunto de datos)
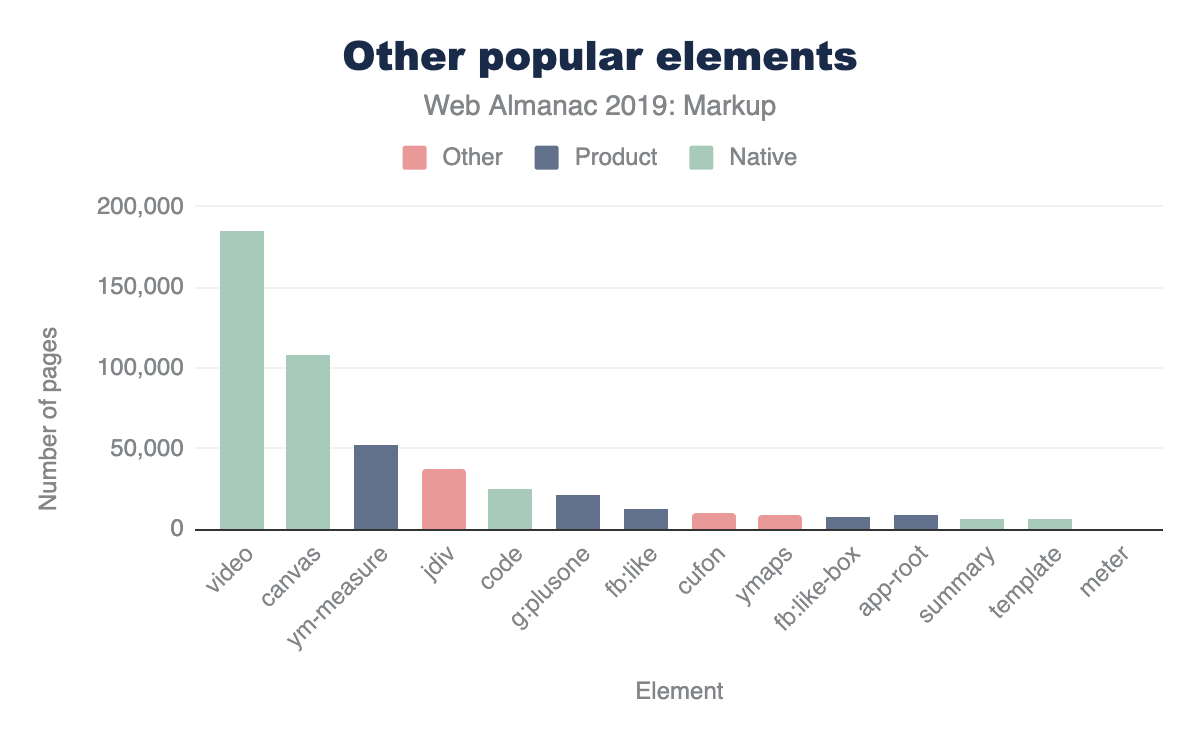
Lo interesante de estos resultados es que también introducen algunas otras formas en que nuestra herramienta puede ser muy útil. Si estamos interesados en explorar el espacio de los datos, un nombre de etiqueta muy específico es solo una medida posible. Definitivamente es el indicador más fuerte si podemos encontrar un buen desarrollo de “jerga”. Sin embargo, ¿qué pasa si eso no es todo lo que nos interesa?
Casos de uso comunes y soluciones
¿Qué pasaría si, por ejemplo, estuviéramos interesados en las personas resolviendo casos de uso comunes? Esto podría deberse a que estamos buscando soluciones para casos de uso que tenemos actualmente, o para investigar de manera más amplia qué casos de uso común están resolviendo las personas con miras a incubar algún esfuerzo de estandarización. Tomemos un ejemplo común: pestañas. A lo largo de los años ha habido muchas solicitudes de cosas como pestañas. Podemos usar una búsqueda rápida aquí y encontrar que hay muchas variantes de pestañas. Es un poco más difícil contar el uso aquí ya que no podemos distinguir tan fácilmente si aparecen dos elementos en la misma página, por lo que el conteo provisto allí conservadoramente simplemente toma el que tiene el mayor conteo. En la mayoría de los casos, el número real de páginas es probablemente significativamente mayor.
También hay muchos acordeones, diálogos, al menos 65 variantes de carruseles, muchas cosas sobre ventanas emergentes, al menos 27 variantes de alternadores e interruptores, y así.
Quizás podríamos investigar por qué necesitamos 92 variantes de elementos relacionados con botones que no son nativos, por ejemplo, y tratar de llenar el vacío nativo.
Si notamos que surgen cosas populares (como <jdiv>, resolviendo chat) podemos tomar conocimiento de las cosas que sabemos (como, que es lo que <jdiv> resuelve, o <olark>) e intenta mirar al menos 43 cosas que hemos construido para abordar eso y seguir las conexiones para inspeccionar el espacio.
Conclusión
Entonces, hay muchos datos aquí, pero para resumir:
- Las páginas tienen más elementos que hace 14 años, tanto en promedio como en máximo.
- La vida útil de las cosas en las páginas de inicio es muy larga. Marcar como obsoleto o descontinuar las cosas no las hace desaparecer, y puede que nunca lo haga.
- Hay una gran cantidad de marcado roto en la naturaleza (etiquetas mal escritas, espacios faltantes, mal escape, malentendidos).
- Medir lo que significa “útil” es complicado. Muchos elementos nativos no pasan la barra del 5%, o incluso la barra del 1%, pero muchos de los personalizados sí, y por muchas razones. Pasar del 1% definitivamente debería captar nuestra atención al menos, pero tal vez incluso debería ser del 0.5% porque, según los datos, es comparativamente muy exitoso.
- Ya hay un montón de marcas personalizadas por ahí. Viene en muchas formas, pero los elementos que contienen un guión definitivamente parecen haber despegado.
- Necesitamos estudiar cada vez más estos datos y generar buenas observaciones para ayudar a encontrar y pavimentar los senderos.
En este último es donde usted entra. Nos encantaría aprovechar la creatividad y la curiosidad de la comunidad en general para ayudar a explorar estos datos utilizando algunas de las herramientas. (como https://rainy-periwinkle.glitch.me/). Comparta sus observaciones interesantes y ayude a construir nuestros conocimientos y entendimientos.

{kind=link}